

이전 시간의 포스트에 이어서 S3를 다루는 두번째 시간입니다.
이전 포스트는 Object Storage Architecture에 대해서 먼저 확인하는 시간을 가졌었습니다.
Amazon S3 : 1. Object Storage 아키텍처
Amazon S3은 많은 서비스 엔지니어들이 익숙한 스토리지입니다. 2006년부터 지금까지 엄청난 스케일의 작업들을 문제없이 처리하고 있습니다. 초당 10억개의 Request 처리 초당 400 terabits 처리 280 trilli
ray5273.tistory.com
이번 포스트에서는 S3가 스케일을 늘림으로써 고민해야했던 부분들에 대해서 정리를 해 보려고 합니다.
지난 포스트에서 아래와 같은 내용이 있었죠.
AWS S3는 아래 요청들을 모두 처리하고 있습니다.
1. 초당 10억개의 Request 처리
2. 초당 400 terabits 처리
3. 280 trillion object를 저장
S3의 발전사를 가늠해보기 위해서 S3 릴리즈 타임라인을 먼저 보도록 하겠습니다.
S3 제품 릴리즈 타임라인
2006 - S3 발표 : S3가 정식 릴리즈 되었습니다.
2012 - Glacier 발표 : 데이터 아카이빙과 백업을 위한 저렴한 서비스
2013 - S3 Intelligent-Tiering : Cost-effective tier에 자동으로 데이터를 배치해주는
2015 - Standard-Infrequent Access 발표 : 접근을 자주 하지 않지만, 필요시 빠른 access가 필요한
2018 - Glaicier Deep Archive 발표 : 데이터를 retrieve 하는 시간이 느리지만 (12시간) 저렴한
2020 : Strong read-after-write consistency 발표
2021 - Object lambda 발표 : 고객이 S3 GET 요청에 자체 코드를 추가해서 애플리케이션으로 반환되는 데이터를 수정 가능하게 지원함.
2023 - S3 Express 발표 : 10배 개선된 latency 지원 그리고 50% 저렴한 요청 가격
이렇게 S3 서비스를 각자의 목적에 따라서 최적의 제품을 사용할 수 있도록 개선되어 왔습니다.
그러면 이런 개선점들을 반영하기 위해서 기술이 어떤식으로 발전해왔는지를 알아보겠습니다.
아키텍처 Overview
S3는 300개가 넘는 마이크로 서비스로 구성되어있다고 합니다.
그런 복잡한 서비스를 하이레벨 관점에서 아키텍처를 아래와 같은 4가지 그룹으로 나눌 수 있습니다.
- 프론트엔드 그룹 (영어로는 fleet이라고 하나봅니다.)with REST API
- Namespace Service
- HDD로 구성된 스토리지 그룹
- Replication이나 Tiering 작업 등을 하는 스토리지 관리 그룹
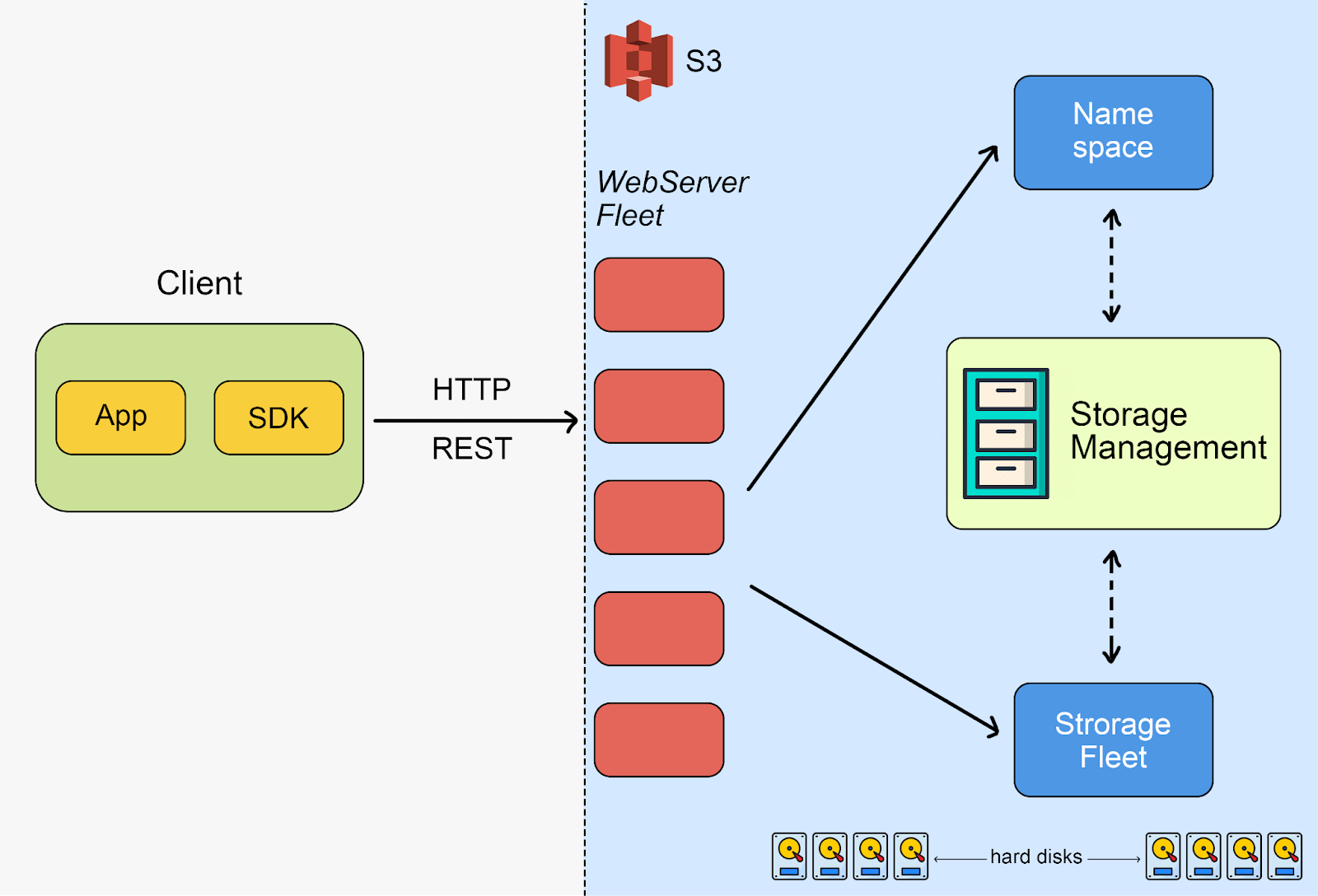
Storage 그룹
S3는 실제로는 단지 아주아주아주 많은 (수백만의) 하드디스크로 이루어진 큰 시스템입니다.
핵심은 스토리지 노드 서버인데요. 그것들은 단순하게 Object들을 하드디스크에 저장하는 Key-value 저장소 입니다.
또한 노드 서버들은 전체 오브젝트 데이터의 조각(Shard)만 처리하고, 컨트롤 플레인은 많은 다른 노드들에 replicating합니다.
AWS는 ShardStore라는 스토리지 백엔드를 만들었습니다.
ShardStore의 내부적으로는 쓰기 증폭을 줄이기 위해 트리 외부에 샤드 데이터가 저장된 간단한 Log-Structured Merge Tree(LSM 트리)로 되어있습니다.
이는 soft-updates-based crash consistency 프로토콜을 사용합니다. (이는 극단적인 concurrency를 지원하기 위해 디자인 되어있습니다). 이 방식은 효율적인 HDD IO를 지원하기 위해서 다양한 최적화를 사용하고있습니다.
더 자세한 내용은 아래의 SOSP 논문에서 확인할 수 있습니다.
using-lightweight-formal-methods-to-validate-a-key-value-storage-node-in-amazon-s3-2.pdf
핵심 : 하드디스크
하드디스크는 오래된 기술이라 항상 모든 use case에서 좋지는 않습니다.
HDD는 IOPS가 제한적이고 Seek latency와 물리적인 결함을 포함합니다.
1956년에는 3.75MB의 드라이브가 $9000 였습니다.
2024년에는 26TB 드라이브가 존재하고 1TB의 가격이 $15 입니다.
이를 봤을때 HDD는 지수적인 발전을 했다고 확인할 수 있습니다.
1. 가격 : 바이트당 6,000,000,000 배 쌉니다.
2. 용량 : 7,200,000 배 커졌습니다.
3. 크기 : 5,000배 작아졌습니다.
4. 무게 : 1,235배 줄었습니다.
이런 발전에도 하나의 문제가 있는데요. IOPS입니다.
HDD는 120 IOPS에서 꽤 오랫동안 멈춰있었습니다.
비슷하게 Latency도 비슷하게 발전했기에 위의 4가지 개선만큼은 아니였습니다.
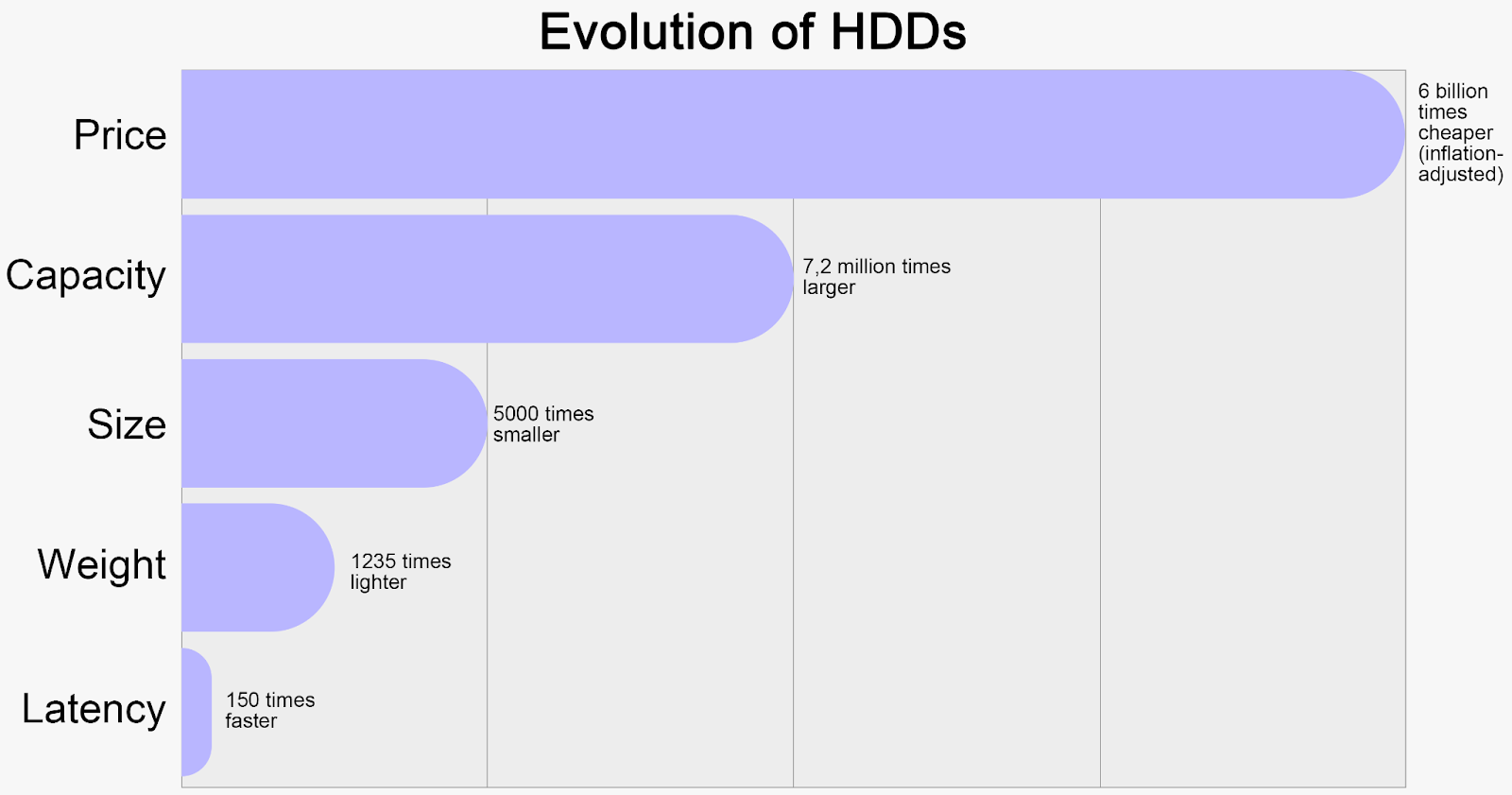
즉, HDD는 바이트당 속도가 느려지고 있다는 것이죠.
따라서, Latency가 중요한 현대세상에서는 HDD를 사용해서 시스템의 요구사항을 유지하기가 어려운 일입니다.
하지만, S3는 방법을 찾아냈습니다.
Parallel IO를 아주 많이 활용하는 방법으로 말이죠.
Replication
스토리지 시스템에서 중복처리는 일반적으로 많이 쓰입니다.
그 중복처리는 durability와 많이 연관이 있습니다.
HDD의 고장에 대비해 데이터를 지키기 위해서 입니다. ( 디스크가 하나 고장나더라도 다른 디스크에 동일 데이터가 남아있어서 데이터를 잃지 않을 수 있죠)
열 관리는 이런 이중화 체계에서 과소평가되고 있습니다. 이러한 체계는 로드를 분산하고 시스템에 균형잡힌 방식으로 읽기 트래픽을 전달할 수 있는 유연성을 제공합니다.
S3는 Erasure Coding을 사용합니다.
이런 방식을 사용해서 데이터를 분산해서 저장하고 데이터 복구가 가능하도록 합니다.
즉, 이 알고리즘으로 몇개의 디스크가 동시에 고장나도 복구가 가능하게 합니다.
Replication은 내구성 관점에서는 아주 비싼 특성입니다. ( 데이터를 얼마나 추가로 더 써놓을 것이냐가 바로 추가 비용입니다.)
반면, I/O 관점에서는 효율적인 특징을 가집니다.
그래서 S3에서는 위의 장단점을 잘 섞어서 사용합니다. 그래서 너무 많은 데이터를 쓰지 않고 ( 3배로 데이터를 복사하고 있지는 않다고 합니다.) I/O는 유연성 있게 제공하도록 하는것이죠.
Sharding (샤딩)
S3는 가능한 만큼 많이 Shard (조각) 들을 넓게 저장하려고 합니다.
S3는 1만개 이상의 고객의 데이터를 수백만 HDD에 나누어서 저장한다고 합니다.
샤딩은 아래와 같은 이득을 만들어줍니다.
1. 급격한 시스템 영향 방지 (Hot Spot Aversion)
: 데이터가 잘 나눠져있으면, 특정 고객이 시스템에 급격하게 영향을 주는것 (Hot Spot 이라고도 합니다)를 막을 수 있습니다. Hot spot은 종종 문제를 일으키므로 피해야합니다.
2. Burst IO 처리 (Burst Demand)
: 1번과 비슷하게 극단적인 Parallelism (병렬처리)는 Burst IO를 처리할 수 있게 됩니다.
3. 훌륭한 내구성 (Durabililty)
: Shard를 더 많이 분산시킬수록 durability가 더 높아집니다.
4. Read 증폭이 없음 (No Read Amplification)
: Read 증폭의 의미는 얼마나 많은 디스크가 단일 read seek 문제를 일으키는지에 대한 것입니다.
동일한 하드웨어를 가정했을때, 하나의 읽기는 동일한 disk seek을 의미합니다.
데이터가 넓게 퍼져있으면, 그런 seek들은 동일한 디바이스에서 일어나지 않습니다.
HDD가 Seek을 덜 할수록 더 좋습니다. 이 특징은 높은 latency의 가능성을 낮출 수 있습니다.
Heat Management at Scale
규모가 커지면서 S3의 큰 문제중 하나는 IO demand를 관리 및 balancing 하는것입니다.
목표는 하나의 디스크에 오는 요청의 개수를 줄이는 것입니다.
최악의 경우에는 여러 드라이브중 하나의 드라이브에 대해 Burst 한 요청으로 인하여 디스크에 제공하는 제한된 IO 처리 능력보다 높아 문제가 생길 수 있습니다. 이로 인해서 드라이브에 대한 요청이 전반적으로 성능이 저하 될 수 있습니다.
요청을 지연시키면 새 데이터 또는 메타데이터 조회에 대한 Erasure Conding 요청과 같은 소프트웨어 스택 계층을 통해 지연이 증폭됩니다.
이런 문제들로 인해서 데이터의 초기 배치가 중요하지만 S3는 작성 시점에 데이터에 대해 언제 어떻게 엑세스를 할지 모르기에 올바르게 데이터를 배치하기가 까다롭습니다.
S3팀은 시스템 규모와 멀티테넌시로 인해서 이 어려운 문제가 근본적으로 쉬워진다고 합니다.
S3는 소위 워크로드와의 무 관계를 경험합니다. Workload가 충분히 큰 규모로 집계되면 Workload가 일정해 지는 현상입니다!
S3 팀은 대부분의 스토리지 워크로드가 대부분의 시간동안 유휴 상태로 유지된다는 점을 알려줍니다
데이터에 대해 엑세스를 할때만 갑작스러운 피크 부하가 나오고 해당 피크 요청은 평균보다 훨씬 높습니다.

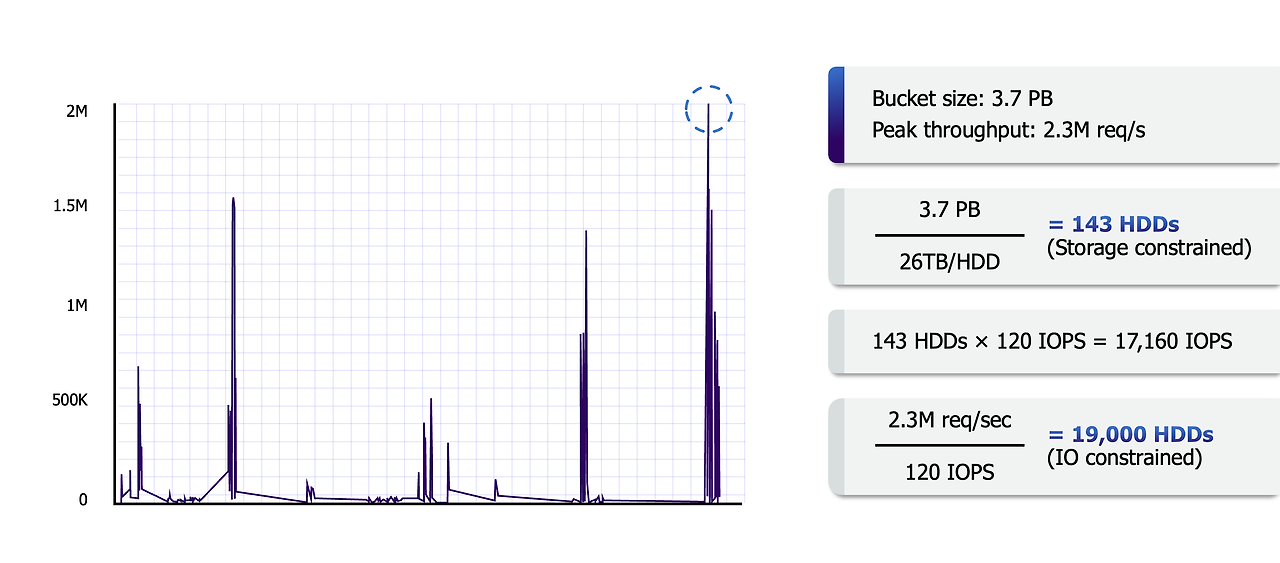
그래서 충분히 큰 규모로 Workload를 집계하는 경우 단일 워크로드가 집계 피크에 영향을 줄 수 없습니다.
그러면 문제를 쉽게 해결할 수 있습니다.
많은 디스크로의 요구에 대한 균형을 맞추기만 하면 됩니다.
Parallelism
Parallelism은 AWS와 고객들에게 모두 도움을 줄 수 있습니다.
고객에게 더 나은 성능, 그리고 S3의 Workload에 대한 decorrelation을 AWS에게 줄 수 있습니다.
두 가지 예시를 들 수 있습니다.
예시 1. 3.7PB 의 S3 Bucket가 있고 초당 230만 IO가 있다고 가정합니다.
3.7PB는 26TB 디스크로는 143개의 드라이브가 필요합니다.
하지만 디스크당 120 IOPs의 성능으로는 19,166개의 드라이브가 필요합니다.
그건 13,302% 의 드라이브가 더 필요한것이죠.

반대의 예시를 들어보죠
예시2. 28PB의 S3 Bucket이 있고, 초당 8,500 IO가 있다고 가정합니다.
120 IOPs의 성능으로 71개의 드라이브가 필요합니다.
반면 26TB의 디스크로는 1076개의 드라이브가 필요합니다.
이것은 1,415% 의 드라이브가 더 필요합니다.

두 가지 예시에서 모두 성능과 용량의 밸런스가 맞지 않죠.
Parallelism으로 이를 해결하려고 했습니다.
S3는 아래의 두 방법으로 Parallelism을 활용합니다.
1. 서버간 Parallelism
하나의 클라이언트와 하나의 connection을 통해서 하나의 S3 endpoint에 file을 요청하는것 대신에,
user는 가능한 많이 connection을 만들도록 합니다.
이런 방식을 통해서 스토리지 시스템의 분산 되어 있는 다른 endpoint를 활용해서 하나의 서버가 부하를 너무 받는것을 막습니다.
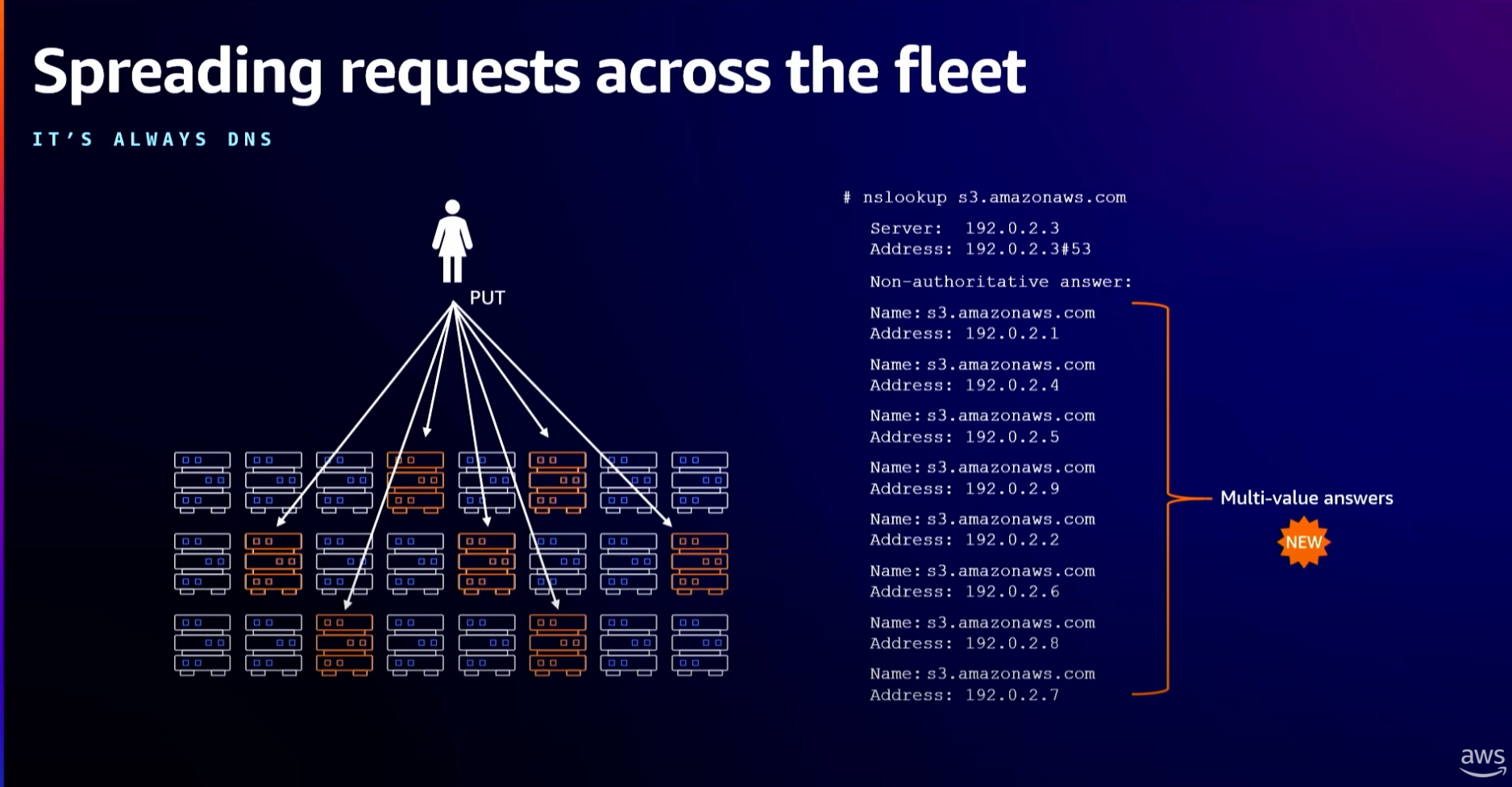
2. Intra-operation Parallelism
커넥션에서 하나의 operation에서도 S3는 Parallelism을 활용합니다.
- 쓰기 : PUT request는 multipart upload를 지원합니다.
- AWS는 multi-thread를 이용한 Throughput 향상을 선호합니다.
- 읽기 : GET request는 비슷하게 HTTP 헤더에서 Object의 특정 영역을 읽는 것을 지원합니다.
- AWS는 하나의 object 읽기를 하는것 보다 여러 요청을 모으는것을 선호합니다.
- 이런 경우에는 요청이 중단되어도 Retry 시간을 개선할 수 있습니다.

Metadata 및 Strong Consistency로의 변경
2020년에 S3는 Strong Read-After-Write Consistency를 릴리즈했습니다. (기존에는 Eventual Consistency 였습니다.)

Strong Consistency의 의미는 고객이 하나의 object를 쓰거나 덮어쓰기를 하면 모든 이후의 읽기는 가장 최신의 데이터를 리턴합니다.
반면 기존의 Eventual Consistency는 항상 최신의 데이터를 리턴하지는 않았습니다.
언젠가 (Eventually) 모든 서버의 데이터가 동기화 되어 최신의 데이터를 리턴할것이라 기대하는 방식이였지요.
S3에서 이것은 엄청난 변경이었는데요.
특히, 이 변경을 하면서 성능, Availability 혹은 Cost에 전혀 영향을 주지 않도록 하는게 핵심이였습니다.
기존 방식 (Eventual Consistency)
S3에는 객체별 Metadata를 저장하기 위한 개별의 하위 시스템이 존재합니다.
메타데이터 읽기/쓰기는 대부분의 요청에 대한 중요한 데이터 경로이기에, 시스템의 Persistent Layer는 복원력이 뛰어난 캐싱 기술을 사용하도록 설계되어, 이 Layer가 손상된 경우에도 S3 요청이 성공할 수 있습니다.
즉, 쓰기는 캐시 인프라에 써지고, 읽기는 Stale 되어 버린 다른 부분을 쿼리해서 예전의 데이터를 읽어오는 경우가 생깁니다.
이것이 S3가 Strong Consistecy가 아닌 Eventual Consistency가 된 주요 원인이었습니다.
새로운 방식 (Strong Consistency)
Strong consistency를 위해서 S3는 새로운 Replication 로직을 Persistence Layer에 넣었습니다.
Cache Coherency protocol의 중요한 조각으로써, 이 기능은 Cache가 실제 Object가 stale하다는것을 알 수 있도록 설계했습니다.
새로운 컴포넌트는 목격자 (witness) 와 같이 행동하여 S3 읽기전에 쓰기/읽기의 배리어 역할을 합니다.
컴포넌트가 읽으려는 값이 stale 함을 알게된다면, cache에서부터 그 값을 invalidate하고 persistence layer에서 값을 읽어옵니다.
내구성 문제
S3는 11 nine의 내구성을 보장하고 있습니다. ( 99.999999999%)
평균적으로 1년에 0.000000001%의 object를 잃어 버릴 수 있는 특징입니다.
그런데 이런 내구성은 쉽게 보장되는것이 아닙니다.
Hardware Failure
11nine의 내구성을 지원하기 위해서 하드디스크의 고장을 S3 scale에서 해결해야합니다.
S3 스케일에서는 매 시간마다 하드디스크의 고장이 일어 날 수 있죠.
이론적으로는 내구성은 해결하기 쉽습니다.
HDD가 고장나면 고치면 됩니다. repair rate가 failure rate와 동일하면 데이터는 안전합니다.
그래서, 실제로 이런 과정을 보장하기 위해서 예측 못하는 실패에도 대비하기 위해서 시스템을 만들어야합니다.
( 실제 AWS가 알려준 예시는 더운 기후로 인해서 데이터 센터가 정전이 생기고, cooling system이 멈춰서 디스크가 고장나기 시작했다고 합니다.)
AWS는 지속적인 자가 회복 시스템을 만들었습니다. (failure 확인 과 repair를 잘 확인할 수 있도록요)
백그라운드로는 내구성 모델이 원하는 내구성을 맞출 수 있도록 지속적으로 트래킹하고있습니다.
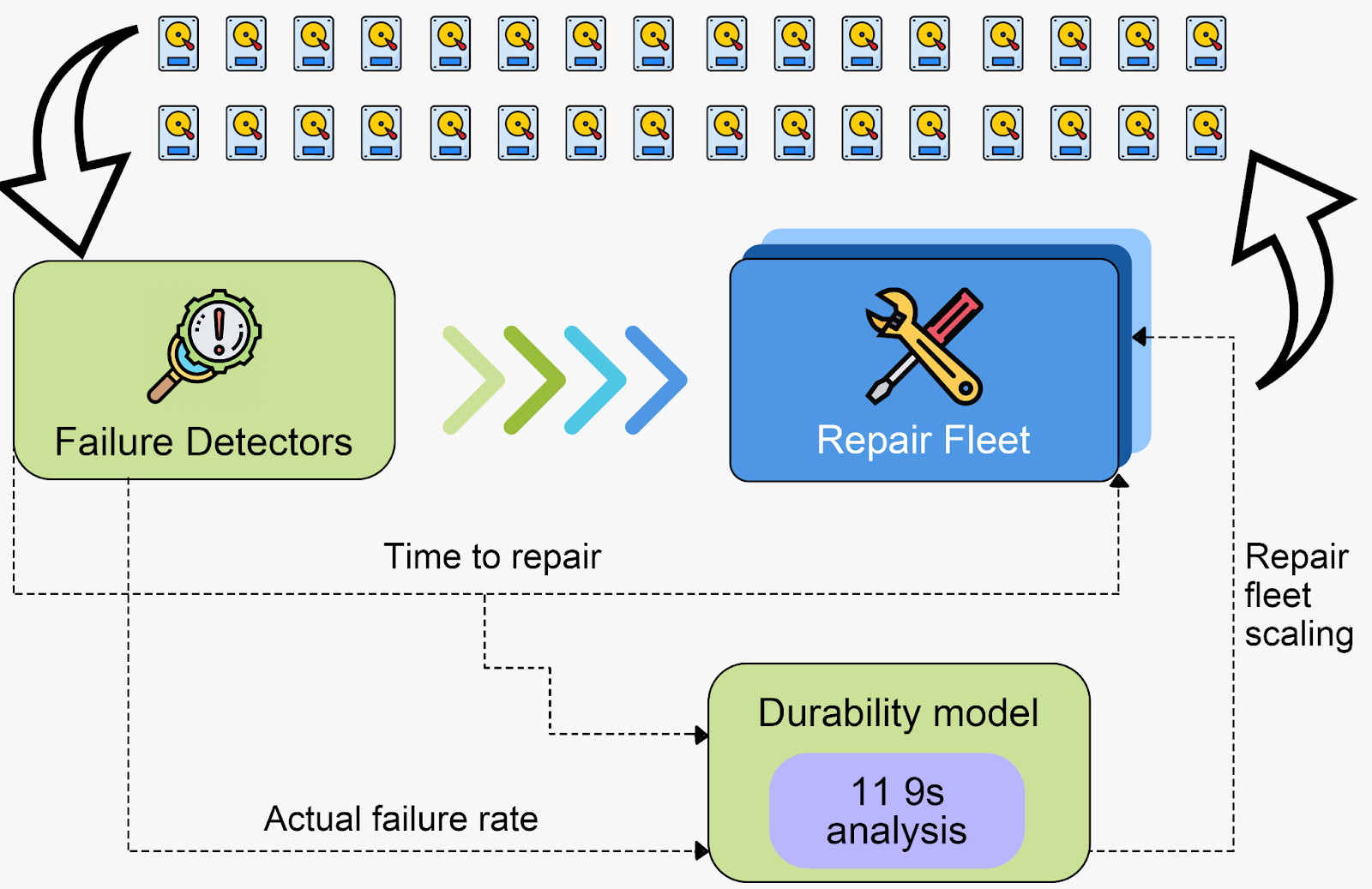
Culture
AWS는 "Durability Threat Model" 접근이라는것을 공유했습니다.
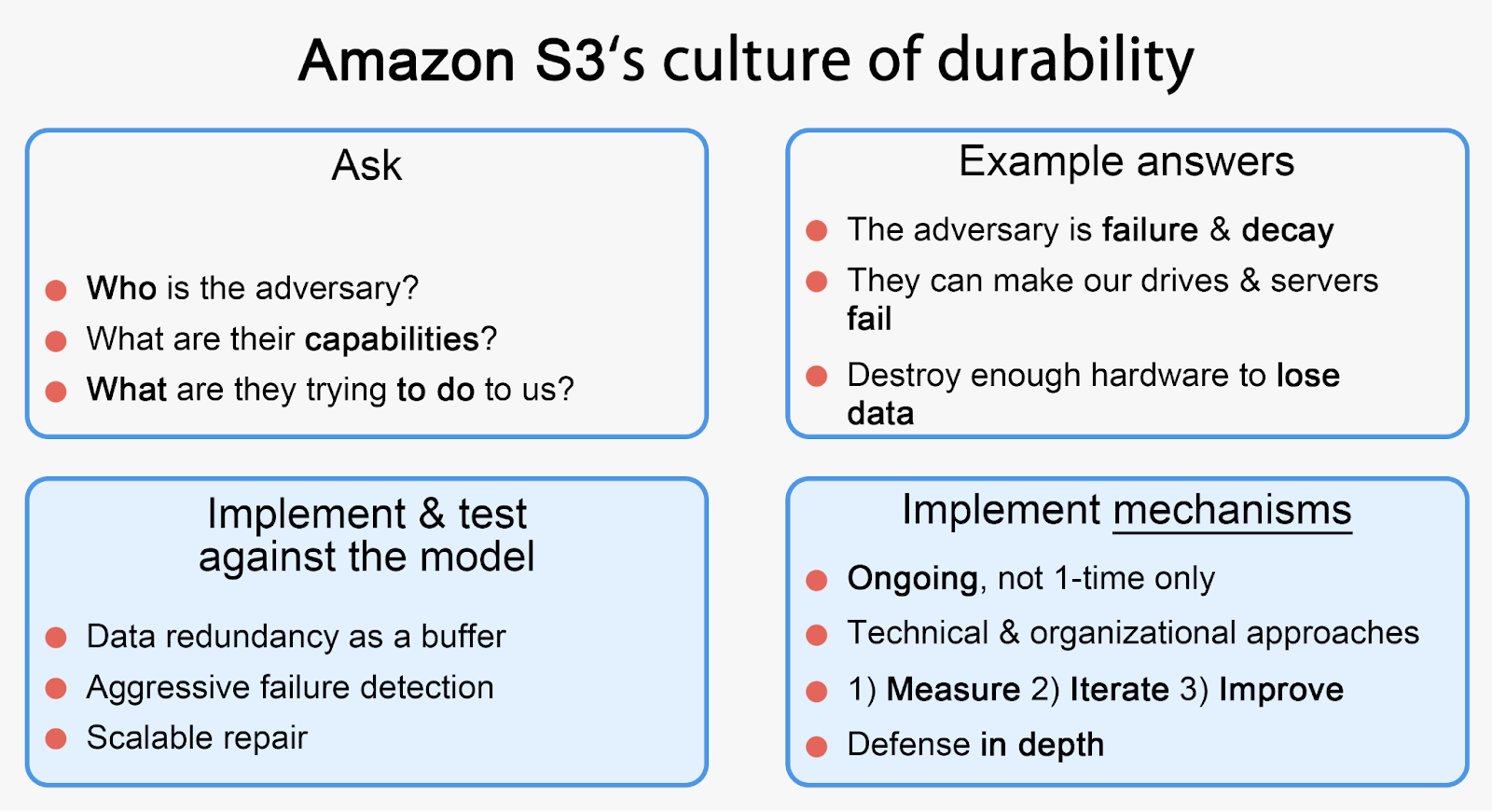
AWS S3의 아키텍처 접근 방식을 요약하자면 아래와 같습니다.
요약
1. Disk의 IOPS를 보완하기 위해 : Sharding과 Parallel Read로 해결.
2. Disk 고장을 보완하기 위해 : Replication 및 Erasure Coding을 활용해서 해결.
3. 11 nine의 내구성을 유지하기 위해 : Durability Threat Model로 해결.
부록 : 또 다른 Performance Optimization 방법 - Prefixes
S3는 1초당 3500개의 Write와 5500개의 read를 특정 파티션 prefix에서 지원한다고 합니다.
각 파티션은 S3가 논리적으로 사용하고 있는 Object Key인데요. Object Key들은 처음에 하나의 파티션에 존재합니다.

Request가 성능 이상의 요구를 한다면 503 slowdown 에러를 보내며, S3는 하나의 파티션의 성능 한계를 넘는다고 생각해 새로운 파티션을 버킷에 생성합니다.
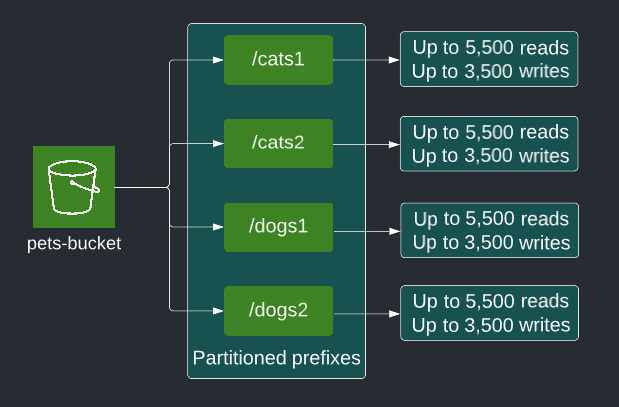
이를 통해서 더 높은 성능을 지원합니다.
그런 Amazon S3에서 성능 중 Latency는 Key 이름에 크게 의존한다고 합니다.
S3는 Key 생성에 있어서 다음을 고려하고있습니다.
- 키 이름 시작부분에 더 가변성이 있는 (정확하게는 겹치지 않는) Key 명명 체계를 사용해서 인프라 내부의 Key 겹침을 방지합니다. (처음 6~8자의 영숫자 또는 16진수 해시코드 같은걸 쓰면 다른 Key와 덜겹쳐서 속도가 빨라집니다.)
- 적절한 태그 설정
- Key 이름에 날짜를 추가하기

요청 속도 처리에 폴더 구성 및 키 이름 지정이 모두 포함되므로 폴더를 내부에서 너무 많이 사용하면 데이터를 가져오는 속도가 훨씬 느려질 수 있습니다.
부록2 : CloundFront - CDN
더 낮은 Latency와 높은 전송속도를 지원하기 위해서 CloudFront라는 CDN을 사용하고있습니다.
유저의 S3 컨텐츠를 viewer와 가장 가까이 있는 곳에 cache copy를 해두는 목적입니다.
그래서 최소화된 거리로 request에 대한 response를 전달해 줄 수 있기 위함입니다.
CloudFront는 TLS Sesseion resumption, TCP fast open, OCSP staping, S2N , 그리고 request collapsing과 같은 방법을 통해서 성능을 추가로 최적화했습니다.
참고 문서
Behind AWS S3’s Massive Scale
This is a guest article by Stanislav Kozlovski, an Apache Kafka Committer. If you would like to connect with Stanislav, you can do so on Twitter and LinkedIn. AWS S3 is a service every engineer is familiar with. It’s the service that popularized the noti
highscalability.com
Amazon S3 Update – Strong Read-After-Write Consistency | Amazon Web Services
When we launched S3 back in 2006, I discussed its virtually unlimited capacity (“…easily store any number of blocks…”), the fact that it was designed to provide 99.99% availability, and that it offered durable storage, with data transparently store
aws.amazon.com
Building and operating a pretty big storage system called S3
Three distinct perspectives on scale that come along with building and operating a storage system the size of S3.
www.allthingsdistributed.com
Building and Operating a Pretty Big Storage System (My Adventures in Amazon S3) | USENIX
@inproceedings {285805, author = {Andy Warfield}, title = {Building and Operating a Pretty Big Storage System (My Adventures in Amazon S3)}, booktitle = {21st USENIX Conference on File and Storage Technologies (FAST 23)}, year = {2023}, address = {Santa Cl
www.usenix.org
'CS 지식 > 아키텍처' 카테고리의 다른 글
| Amazon S3 : 1. Object Storage 아키텍처 (0) | 2024.03.23 |
|---|
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.
