

Lustre Overview
Lustre는 오픈소스 프로젝트로, 높은 확장성(Scalability), 고가용성(High availability), 성능(High performance)을 지원하는 분산형 병렬 파일 시스템입니다.
Lustre는 아래와 같은 특징을 가지고 있습니다.
1. 대규모 스케일에서 최고의 성능을 발휘하도록 설계
2. Exa-byte Scale 용량을 지원
3. 최대 규모의 슈퍼컴퓨터에서 사용할 수 있는 최고의 IO 성능
4. POSIX (Portable Operating System Interface for Unix) 호환
5. Efficient and cost effective
Lustre 파일 시스템은 수백 테라바이트의 작은 플랫폼에서 수백 페타바이트의 대규모 플랫폼까지 POSIX 호환되는 단일 네임스페이스로 지원이 가능합니다.
단일 파일 시스템 인스턴스를 위한 Lustre 서버는 수천개의 컴퓨팅 클라이언트에 최대 수십 페타바이트의 스토리지를 동시에 제공할 수 있으며, 초당 1테라 바이트 이상의 throughput을 제공할 수 있습니다.
최근에 많이 사용하는 AI의 예시를 들어보면 아래와 같이 사용할 수 있을것 같습니다.
예시 : 딥러닝 클러스터
환경 설정:
- 파일 시스템 용량: 10PB
- 클라이언트 수: 1000대의 GPU 서버
- 목적: 대규모 딥러닝 모델 훈련
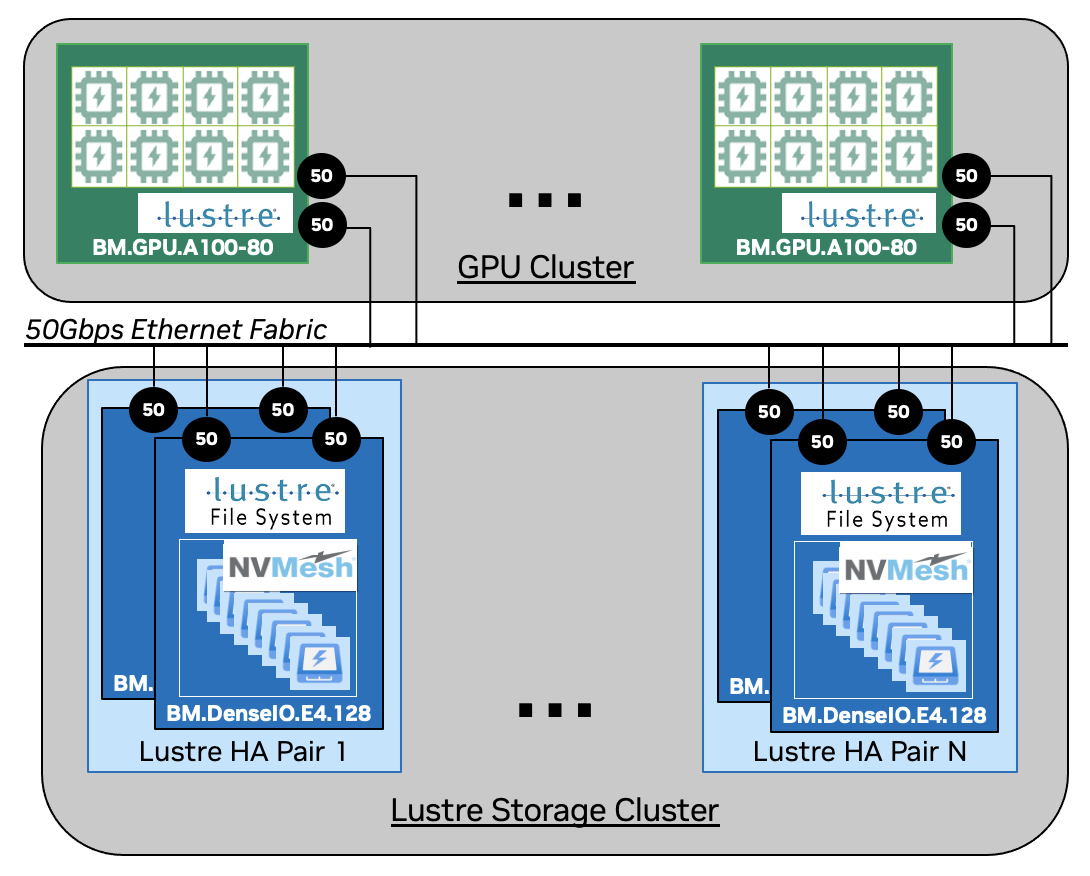
설명:
- 파일 시스템 구성:
- Lustre 파일 시스템을 설정하여 10PB의 스토리지 용량을 제공합니다.
- GPU 서버 동시 접근:
- 1000대의 GPU 서버가 Lustre 파일 시스템에 마운트됩니다.
- 각 서버는 딥러닝 모델 훈련을 위해 대규모 데이터 세트를 읽고 씁니다.
- 데이터 스트라이핑을 통해 각 서버는 병렬로 데이터를 접근하여 훈련 속도를 극대화합니다.
- 데이터 처리:
- 딥러닝 모델 훈련에 필요한 대규모 데이터 세트(예: 이미지, 비디오, 텍스트 데이터)가 Lustre 파일 시스템에 저장됩니다.
- 각 GPU 서버는 Lustre 파일 시스템에서 데이터를 병렬로 읽어들여 모델 훈련을 수행합니다.
- 훈련 결과와 체크포인트는 Lustre 파일 시스템에 저장됩니다. 이는 모델 재훈련과 검증에 사용됩니다.
- 성능 최적화:
- Lustre의 높은 I/O 성능을 활용하여, GPU 서버가 데이터에 빠르게 접근할 수 있습니다.
- 모델 훈련 과정에서 I/O 병목을 최소화하고, 훈련 속도를 최적화합니다.
비슷한 환경의 실제 예시도 참고 링크에 존재합니다.
Lustre 파일 시스템
Lustre는 client-server (클라이언트-서버), parallel (병렬), distributed(분산), network file system입니다.
Lustre는 분산 파일 시스템의 한 유형인 병렬 파일 시스템으로, 주로 HPC의 대용량 파일 시스템으로 사용되고 있습니다.
소규모 클러스터 시스템부터 대규모 클러스터까지 사용되는 고성능 파일 시스템입니다.

러스터 내부는 세 가지 다른 클래스의 서버로 구성 되어 있습니다.
관련 용어들과 함께 정리를 해봤습니다.
1. Management Server
MGS (Management Server, 서버) : 모든 러스터 파일 시스템에 대한 구성 정보를 클러스터에 저장하고 이 정보를 다른 러스터 호스트들에게 제공합니다.
MGT (Management Target, 디스크) : 모든 러스터 노드에 대한 구성정보가 MGS에 의해서 디스크에 적힙니다. (HDD or SSD)
2. Metadata Server
MDS (Metadata Server, 서버) : 러스터 파일 시스템의 모든 네임스페이스를 제공하며, 파일시스템의 inode를 저장합니다.
파일 열기, 닫기, 삭제 및 이름 변경, 네임스페이스 관리를 합니다.
MDT (Metadata Target, 디스크) : MDS의 메타데이터 정보가 적히는 디스크입니다. (HDD or SSD)
3. Object Storage Server
OSS (Object Storage Server, 서버) : 하나 이상의 로컬 OST에 대한 파일 서비스 및 네트워크 요청 처리 합니다.
OST (Object Storage Target, 디스크) : OSS에 설치되어 실제로 데이터를 저장합니다. (HDD or SSD)
하나의 파일은 1개 혹은 그 이상의 object로 구성 될 수 있으며, 파일의 데이터는 여러 object에 걸쳐서 striping 될 수 있습니다.
즉, 하나의 러스터 파일은 많은 스토리지 디스크에 걸쳐 여러개의 Object로 구성될 수 있습니다.
그리고 데이터를 저장하거나 읽기를 요청하는 Lustre 클라이언트가 있습니다.
4. Lustre 클라이언트
Lustre 클라이언트는 각 러스터 파일시스템 인스턴스를 Lustre Network Protocol (LNet)을 통해서 마운트합니다.
또한, POSIX 호환 file system을 제공합니다.
따라서, POSIX system call을 사용하는 어플리케이션은 Lustre를 위해서 특별한 작업을 해줄 필요가 없습니다.
Lustre Networking Protocol (LNet)
클라이언트가 파일시스템에 엑세스하는데 사용하는 고속 데이터 네트워크 프로토콜입니다
TCP/IP, RDMA, Intel Omni-Path Architecture (OPA) 그리고 infiniband를 지원합니다.
클라이언트는 POSIX API를 통해서 metadata와 Object 데이터를 요청하고 그것들을 모아서 사용자에게 전달합니다.
클라이언트는 Storage에 직접적으로 접근할 수 없고 모든 I/O는 network를 통해서 전달됩니다.
Lustre와 리눅스
러스터가 리눅스 기반인 이유는 아래 두 가지 파일 시스템을 사용하기 때문입니다.
1. LDISKFS (리눅스 EXT4로 부터 발전함)
| 장점 | 단점 |
| 고성능과 낮은 지연시간 | 데이터 무결성 보호나 스냅샷 압축등 기능이 없음. |
| EXT 4 기반의 안정성 | EXT4 기반이라 매우 대규모 데이터 관리에 한계가 있음. |
| 관리와 설정이 간단, 호환성 높음 |
2. ZFS ( OpenSolaris 에서 Linux로 포팅됨)
| 장점 | 단점 |
| 데이터 무결성 (모든 데이터와 메타데이터에 체크섬 확인) | 데이터 무결성 및 고급 기능으로 인해 성능 오버헤드 |
| 스냅샷, 데이터 복제, 압축등의 고급 기능 제공 | 설정과 관리가 복잡함 |
| 매우 큰 용량의 스토리지를 관리 가능 |
위 두 가지 파일 시스템 모두 리눅스 커널을 기반으로 동작하기 때문입니다.
Lustre와 High Availability (HA)
각각 서버의 Target (디스크)들은 active-passive failover resources로 관리되며, 여러 리소스가 동일한 HA에서 실행 될 수 있습니다.
Failover를 자연스럽게 처리 할 수 있도록 Lustre의 data 변경은 비동기식 트랜잭션 방식으로 이루어집니다.
모든 Lustre 서버 클래스(Management, Meta and Object Server)는 Failover를 지원합니다.
따라서, 단일 Lustre 파일 시스템 설치는 일반적으로 여러개의 HA Cluster들로 구성됩니다.
이런 HA 클러스터는 수십 페타바이트의 용량과 초당 1테라 바이트 이상의 처리량으로 확장할 수 있는 HA를 위한 기본 구성 요소입니다.


Lustre와 Scalability

일반적인 Lustre 시스템의 배포 용량은 1~60PB 이며, 워크로드 요구사항에 따라 구성이 크게 달라질 수 있습니다.
이번 포스트에서는 간략하게 Lustre의 전반적인 특징에 대해서 알아보았습니다.
다음 포스트에서는 아래와 같은 좀 더 세부적인 아키텍처 최적화/설계에 대해서 알아보겠습니다.
HSM (Hierarchical Storage Management), PCC (Persistent Client Cache), overstriping, DoM (Data On MDT), DNE (Distributed Namespace Environment)
참고
(1) GPU 1120개와 14PB 스토리지 사용 실제 예시
Accelerating-AI-at-Scale_Julie_Prethvi_updated051421.pdf (opensfs.org)
(2) Lustre Architecture
LustreArchitecture-2017-08-17, v4
(3) Lustre 파일시스템과 GPU Direct 소개
글루시스 기술 블로그
A simple yet classy theme for your Jekyll website or blog.
tech.gluesys.com
(4) Lustre Online Help
Building the System – The High Availability Configuration Spec
Integrated Manager for Lustre Online Help
whamcloud.github.io
'관심 분야 센싱 > 스토리지' 카테고리의 다른 글
| [번역] 노션이 데이터 레이크를 구축하고 확장한 방법 (0) | 2024.08.10 |
|---|---|
| Nearline HDD (0) | 2023.12.31 |
| Solidigm CSAL + Alibaba Cloud (1) | 2023.12.03 |
| Solidigm CSAL이란 (1) | 2023.12.02 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.
![[번역] 노션이 데이터 레이크를 구축하고 확장한 방법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fp35nH%2FbtsI06PUJ9z%2Fvam9UKAfpJRVJXKgbeQ6xK%2Fimg.png)


