

매번 복습 할 때마다 새롭고 자주 까먹는 영역이 Transacion과 ACID인데요.
한번 제대로 정리를 해두고 이를 자주 보면서 까먹지 않기 위해서 글을 써두려고합니다.
Transaction 이란?
- SQL Query의 모음
- 하나의 작업 단위
- 여러 개의 Query가 하나의 작업 단위에 포함 될 수 있습니다.
- 실제 예제로는 돈을 맡기는 케이스가 있습니다.
- SELECT, UPDATE, UPDATE 와 같이 3개의 쿼리가 순서대로 필요합니다.
하나의 예시는 아래와 같습니다.
계좌 1에서 계좌 2로 돈을 보내는 경우 아래와 같이 Transaction이 동작하죠.

Transaction Lifespan
- Transaction BEGIN을 통해서 Transaction을 시작할 수 있습니다.
- Transaction COMMIT을 통해서 실제 Transaction 값들을 디스크에 저장합니다.
- Transaction ROLLBACK을 통해서 Transaction의 변경사항에 대해서 이전의 상태로 되돌립니다.
- Transaction이 비정상적 종료되는 경우 (e.g. crash) => ROLLBACK 을 일반적으로 합니다.
이 모든 동작들은 데이터베이스 종류별로 다르게 처리합니다.
Postgres와 Mysql도 다르고 Oracle, SQL Server도 서로 다른 정책에 따라서 동작합니다.
Transaction의 본질
- Transaction은 데이터를 변경하는데 주로 사용합니다.
- Read-Only transaction도 일반적입니다.
- 예를 들면, 특정 시간의 리포트와 스냅샷을 만들고 싶을 경우 사용합니다.
ACID
데이터베이스를 이해하는데 기본인 ACID에 대해서 알아보겠습니다.
Atomicity
- Transaction의 모든 쿼리들은 반드시 성공해야 합니다.
- 하나의 쿼리가 실패하면, Transaction 내의 실패 쿼리 이전에 성공했던 모든 쿼리들은 Rollback 되어야합니다.
- 그리고, 데이터베이스가 Transaction의 commit 이전에 다운된다면, 데이터 베이스에 적용된 해당 Transaction의 모든 쿼리들은 Rollback 되어야합니다.
아래는 Atomicity의 예시입니다.
Isolation
Database 특성중에서 상당히 중요한 특성입니다.
아래와 같은 질문이 Isolation과 연관이 있습니다.
"현재 진행중인 Transaction이 다른 Transaction에 의한 변경을 확인할 수 있게해야하는가?
이에 대한 대답은 원하는 상황에 따라서 전혀 달라 질 수 있습니다.
이를 Read Phenomena라고 정의를 내릴 수 있으며 아래와 같이 4가지 경우의 수로 나눌 수 있습니다.
Read Phenomena
1. Dirty read
2. Non-repeatable reads
3. Phantom reads
4. Lost updates
Read Phenomena - Dirty Read
Dirty Read의 경우 커밋되지 않은 다른 Transaction의 결과를 읽게 되는 것입니다.
TX1, TX2가 아래와 같이 동시에 실행되는 경우가 있습니다.

1. TX1은 Sales 테이블에서 PID와 QNT*Price를 계산합니다. (Product 1의 QNT는 10)
2. TX2는 1번 직후 Product1의 개수를 5개 늘립니다. (Product 1의 QNT는 15)
3. TX1은 Sales 테이블에서 QNT*Price의 sum을 구합니다. ( 이 경우 2번에서 update된 15를 읽습니다)
그래서 15 * 5 + 20 * 4 = $155로 계산을 하게됩니다.
이것이 바로 Dirty Read의 경우입니다.
즉, 커밋되지 않은 값이 다른 Transaction에서 읽혀지는 것입니다.
4. 그리고 TX2는 COMMIT이 실행되지 않고 Rollback 되버립니다.
이런 경우 3번의 결과는 완전히 잘못된 결과가 됩니다.
Read Phenomena - Non-repeatable Read
Non-repeatable Read는 한 Transaction 내에서 동일한 값에 대해서 Read를 할때 첫 번째와 두 번째 결과가 다르게 되는것입니다.
바로 예시를 보겠습니다.

1. TX1은 PID와 QNT*PRICE값을 계산을 했습니다. (Product 1은 처음에 QNT가 10이었습니다.)
그래서 Product1:50, Product2:80 이라는 값을 얻게되었습니다.
2. TX2가 Product1의 개수를 5개 늘리고 Commit을 해버립니다.
3. TX1이 QNT*PRICE 값을 다시 계산하여 SUM 연산을 합니다.
2번이 실제로 커밋이 되어 버려서 Product 1의 QNT는 15가 되었고 따라서 이에 의해
총 합은 15 * 5 + 20 * 4 = 155가 됩니다.
Dirty Read와의 차이는
Dirty Read는 한 Transaction 내에서 커밋 되지 않은 값을 읽은것이고
Non-repeatable Read는 한 Transaction 내에서 다른 Transaction이 커밋되어 반영 된 값을 읽은 차이가 있습니다.
Read Phenomena - Phantom Read
Phantom Read는 범위를 읽는 경우에 발생합니다.

1. TX1이 SELECT를 합니다. (Product3은 추가되지 않은 상황이라 2개만 읽힙니다.)
2. TX2가 새로운 Product 3의 새로운 Row를 추가했습니다. 그리고 COMMIT됩니다.
3. TX1이 모든 QNT*PRICE 값을 SUM 하는 연산을 합니다.
여기서 원래의 의도는 Product1과 2만 계산하는 거였는데, TX2가 COMMIT 되어 Product 1,2,3의 합이 값으로 연산됩니다.
이 현상이 Phantom Read입니다.
처음에는 없었던 값이 새로 생기는거죠.
Read Phenomena - Lost updates
이 케이스는 원래 의도했던 값이 사라지는 현상입니다.

1. TX1에서 Product1의 개수를 10개 늘립니다. (Product1의 QNT는 10 => 20)
2. 동시에 TX2에서 Product1의 개수를 5개 늘립니다. (Product1의 QNT는 10 => 15) 그리고 커밋됩니다.
3. TX1에서 전체 Sales의 값을 SUM합니다.
이 경우 TX2에 의해 update 된 Product1의 QNT가 15가 되어 원래 의도 했던 20이 무시되고, 15로 계산됩니다.
이것이 Lost updates 현상입니다.
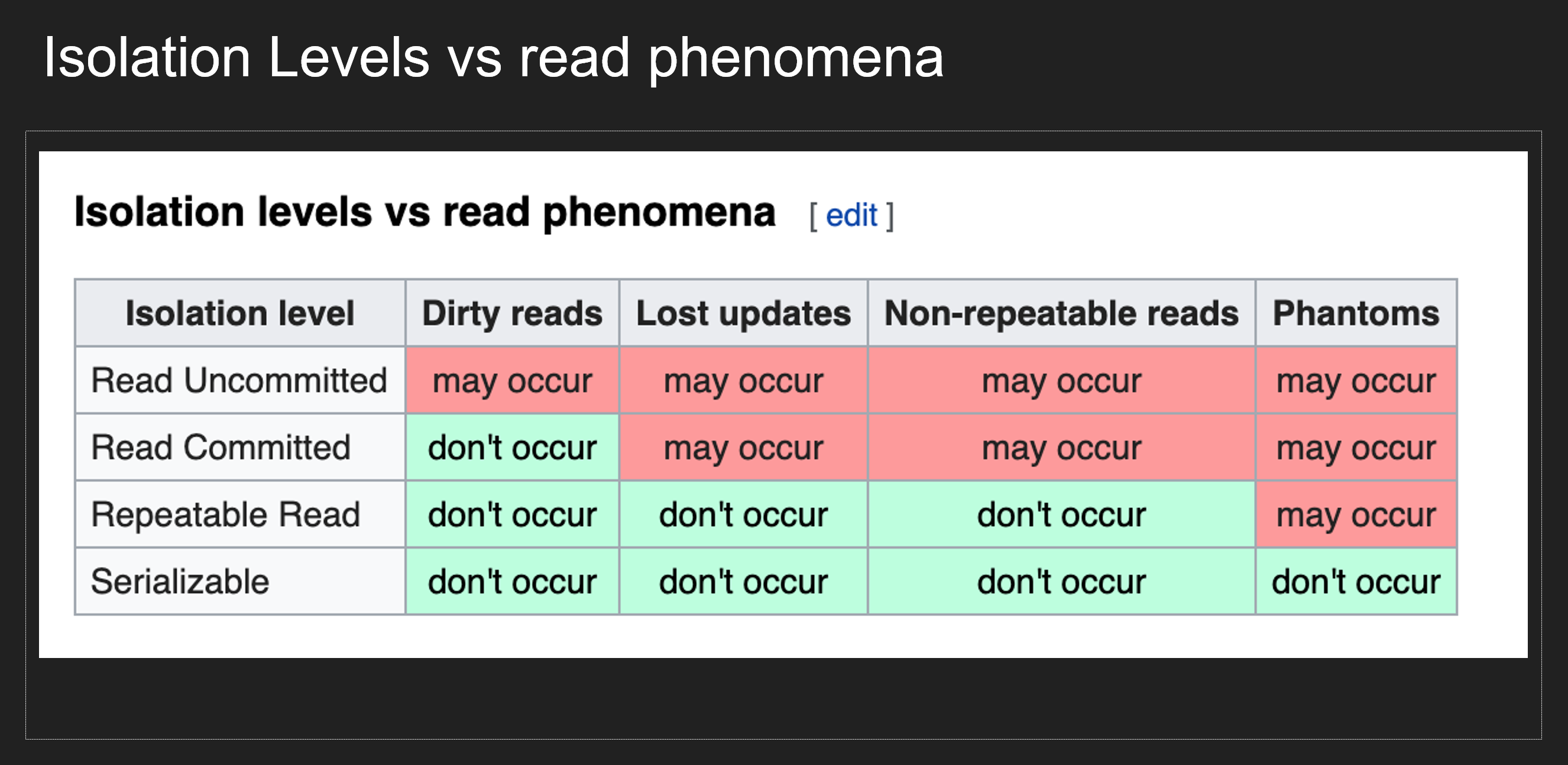
이런 현상들의 분류로 아래와 같이 Isolation을 4가지로 나눌 수 있습니다.
Isolation levels
1. Read uncommitted
- Isolation이 없습니다. 커밋된/되지 않은 모든 변경점은 모두 볼 수 있습니다.
- Dirty Read 발생 가능
2. Read committed
- 다른 Transaction이 commit된 변경 만 볼 수 있습니다.
- Non-Repeatable Read 발생 가능
3. Repeatable Read
- Transaction의 쿼리가 Row를 읽을때 해당 값이 다른 Transaction에 의해서 변경되지 않음을 보장합니다.
- Phantom Read 발생 가능
- 참고로, Postgres에서는 Repeatable Read Level로 Isolation level을 지정하면 Phantom read를 방지해줍니다. (Postgres만 제공하는 특수 기능)
4. Snapshot
- Transaction의 각 쿼리들은 Transaction에 의해서 변경된 값들만 확인이 가능합니다.
- 특정 시점의 데이터베이스를 스냅샷을 떠놓는것과 동일합니다.
5. Serializable
- 모든 Transaction은 한번에 하나만 실행이 가능합니다.
- 성능이 가장 느립니다.
요약하면 아래와 같습니다.
실제 Database의 Isolation 구현 방식
- 모든 DBMS는 Isolation level을 달리합니다.
- Pessimistic한 접근
- Row level로 lock, Table Level로 lock, Page level로 lock합니다.
- Optimistic한 접근
- No locks, 변경 사항에 대해서만 track합니다.
- Repeatable read level은 rows를 lock하는 방식을 일반적으로 씁니다.
- 다만, 너무 많은 row를 읽는 경우 cost가 상당한데요.
- 그래서 Postgres는 Repeatable Read 구현을 Snapshot을 통해 구현했습니다.
Serializable vs Repeatable Read 비교해보기
조금 더 자세히 비교 해 보겠습니다.
아래의 예시에서 Serializable과 Repeatable Read는 큰 차이를 보입니다.
1. 1:"aa", 2:"bb"라는 row가 존재합니다.
2. Transaction 1은 모든 "aa" row를 "bb"로 변경합니다.
3. 동시에 Transaction 2는 모든 "bb" row를 "aa"로 변경합니다.
이 경우 Repeatable Read Isolation의 경우 Transaction1과 Transaction2가 바꾸고자 하는 데이터가 서로 달라 두개의 Transaction이 동시에 실행이 가능합니다.
따라서, 1:"bb", 2:"aa"로 변경이됩니다.
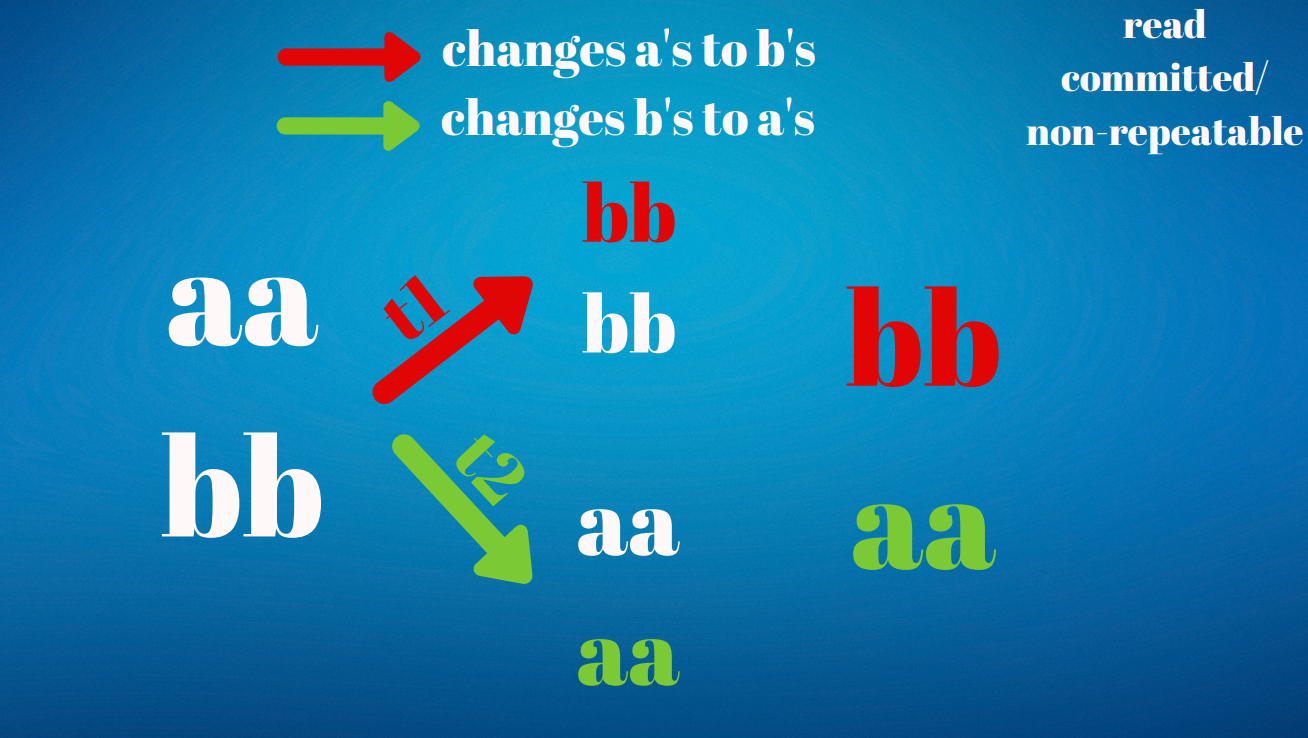
반면 Serializable의 경우 다릅니다.
두개의 Transaction이 동시에 실행 될 수 없습니다.
따라서, 이를 순서대로 실행하게 되고 Transaction 1이 먼저 실행된다고 가정하면 결국은
1. 초기 상태 : 1:"aa", 2:"bb"
2. Transaction 1 : 1:"bb", 2:"bb"
3. Transaction 2 : 1:"aa", 2:"aa"
로 Repeatable Read와 결과가 크게 다르게 됩니다.

Consistency
Data의 Consistency와 Read의 Consistency가 있습니다.
Data의 Consistency를 먼저 보도록 하겠습니다.
Data Consistency
아래와 같은 특징을 가지고 있습니다.
- User에 의해서 정의됩니다. (여기서의 User는 데이터 베이스를 설계한 사람입니다.)
- Referential integrity (foreign keys) 같은 곳에서 사용됩니다.
- Atomicity, Isolation과 연관됩니다.
아래는 Data가 Consistent한 예제 입니다.
테이블 두개가 있는데 Picture_likes의 데이터와 Pictures의 like 데이터가 일치함을 볼 수 있죠
이럴때 Data가 Consistent 하다고 할 수 있습니다.

반면 아래와 같이 Inconsistent 한 경우가 있습니다.
오른쪽 테이블에는 Picture_ID가 1인 like가 총 2개인것이 보이지만 Pictures 테이블에는 5개로 표시가 되어있습니다.

Read Consistency
쉽게는 아래와 같이 표현할 수 있습니다.
1. 데이터를 X로 업데이트하면
2. 해당 데이터를 Read할 때 X 여야합니다.

당연하다고 느껴 질 수 있지만, 실제 시스템에서 이를 완벽하게 보장하려면 쉽지 않습니다.
하나의 예시는
1. 주 데이터 베이스에 데이터 X를 업데이트합니다.
2. 모종의 이유로 인하여 Replication 된 보조 데이터베이스에서 동일한 데이터를 읽으려고합니다.
3. 그런 경우 아직 주 데이터베이스에서 보조 데이터베이스에 데이터 X를 업데이트 하지 않아서 다른 데이터를 읽어오게됩니다.
이런 경우는 실 예시에서는 많이 발생할 수 있습니다.
그래서 Read Consistency에 대한 주요 요지는 아래와 같은 질문으로 요약가능합니다.
"방금 Commit된 Transaction의 변경을 새로운 Transaction이 즉시 확인할 수 있게 하겠는가?"
그래서 이를 지키기 쉽지 않아서 많은 Product에서는 Eventual Consistency (궁극적 일관성) 이라는 용어를 많이씁니다.
Eventual Consistency의 의미는 "당장은 변경사항이 업데이트 되지는 않지만, 결국에는 업데이트되어 있을것이다."
라는 의미입니다.
Eventual Consistency
NoSQL이 나오게 되면서 많이 언급되는 개념입니다.
다만, 반드시 NoSQL에서만 발생하는 개념은 아닙니다.
아래와 같은 상황에서는 모든 Database에서 Inconsistent 하다고 볼 수있습니다.
1. 리더 DB의 값을 X로 업데이트합니다.
2. 팔로워 DB의 값(Z)으로 부터 데이터를 받습니다.
3. 리더 DB가 팔로워 DB에 X값을 Sync합니다.
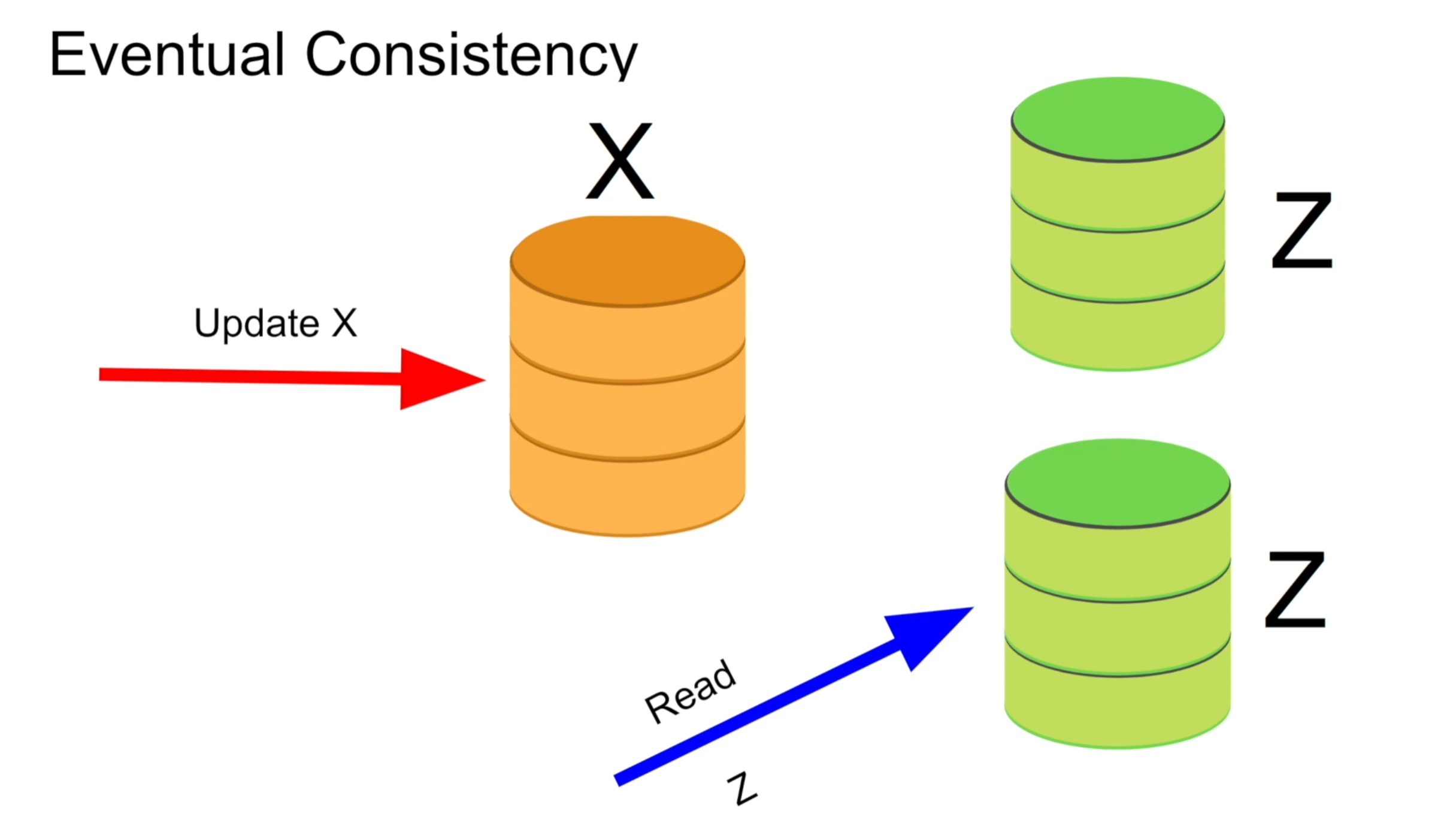
2번과 같은 경우를 Inconsistent 하다고 말할 수 있습니다.
주로 캐시를 도입하는 순간 Consistency가 없어진다고볼 수 있습니다.
캐시 업데이트를 한 순간과 실제 DB를 업데이트하는 순간은 다르기 때문이죠.
그래서 Eventual Consistency라는 것은 이런 경우에도 사용자가 괜찮은지에 따라서 다른것입니다.
입금을 하거나 출금을 하는 경우에 계좌의 돈이 Consistency가 맞지 않아 실제와 다르면 안되겠죠.
반면, 내 글의 좋아요의 숫자가 1000개인지 1001개인지는 크게 중요하지 않으니 Eventual consistency라는 개념으로 보장이 가능할 것입니다.
Durability
이 특성은 커밋 된 Transaction의 데이터가 실제로 SSD나 HDD 같은 휘발되지않는 데이터 디스크에 저장되어야 한다는 것입니다.
Durability를 위한 여러가지 방법론이 있습니다.
1. WAL (Write Ahead Log) - 실제 데이터를 쓰기 전에 각 데이터에 대한 작은 로그 파일을 먼저 저장합니다.
2. Asynchronous Snapshot - 데이터를 쓰는 동안 모든 내용을 메모리에 유지하고 백그라운드에서 비 동기적으로 디스크에 저장하는 방법입니다.
3. AOF (Append Only File) - 변경 사항만을 디스크에 저장하는 방법입니다. 모든 정보를 저장하는게 아니라 변경사항만 저장하므로 가볍고 빠른 방식으로 데이터를 저장할 수 있습니다.
'CS 지식 > 데이터베이스 기본 다지기' 카테고리의 다른 글
| Database Engine 비교하기 (1) | 2024.11.20 |
|---|---|
| 데이터베이스 복제(Replication)란? (0) | 2024.11.17 |
| 데이터베이스 파티셔닝이란? (1) | 2024.11.13 |
| Row Oriented Database vs Column Oriented Database (3) | 2024.10.13 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



