

이전 포스트에 이어서 본 포스트에서는 AWS Seoul Summit 2024의 여러가지 세션들 중 데이터/스토리지와 관련된 세미나를 요약해보려고합니다.
제가 들었던 것 들 중에 2가지를 중점적으로 요약했습니다.
1. AWS로 데이터 레이크 구축하기
AWS로 데이터 레이크 구축하기 세션이 있었습니다.
먼저 데이터 레이크와 데이터 웨어하우스를 정의해보겠습니다.
데이터 레이크 vs 데이터 웨어하우스
| 데이터 레이크 | 데이터 웨어하우스 | |
| 데이터 형태 | - 정형, 반정형, 비정형 데이터를 raw data로저장 (데이터를 정제하지 않고 있는 그대로 저장) |
- 데이터를 구조화 된 형태로 저장 - 업무 분석 요구에 맞춰 데이터를 정제, 가공하여 저장 |
| 스키마 요건 | 사전 스키마 설계 관련 요구 조건 없음 | 데이터 저장전에 스키마 설계 필요 |
| 데이터 신뢰성 | Raw data 형태로 저장하여 데이터 품질은 다소 떨어짐 | 데이터 정제 및 가공 과정을 거치기 때문에 데이터에 대한 신뢰성이 높음 |
| 설계 지향점 | 성능 보다는 스토리지 볼륨과 비용을 우선시하여 설계함 | 빠른 쿼리 성능을 제공할 수 있도록 설계함 |
데이터 레이크의 핵심요소는 아래의 4가지 입니다.
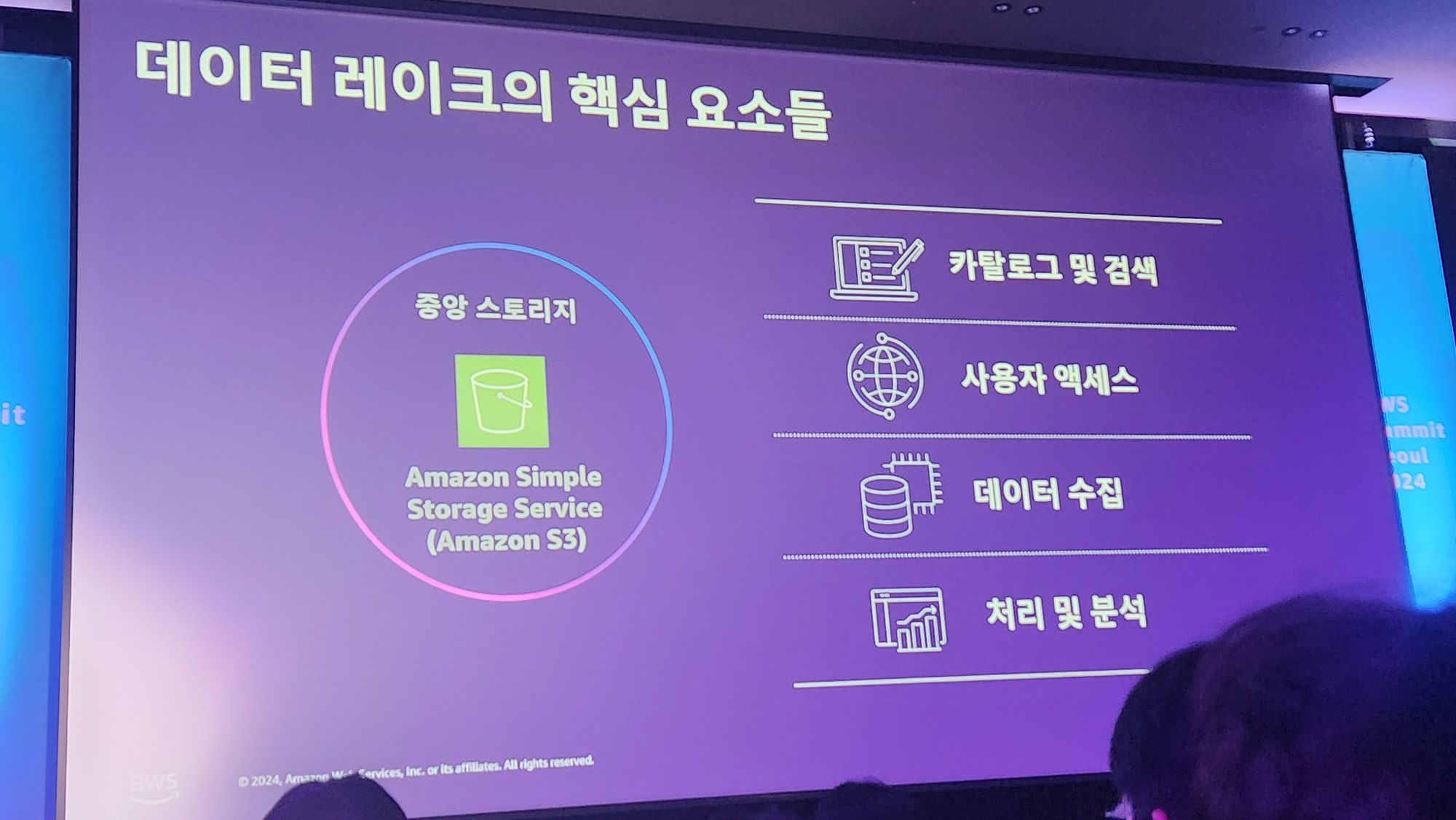
데이터 레이크 하우스란 데이터 레이크와 데이터 웨어 하우스의 장점만을 모은 형태를 의미합니다.
AWS에서의 데이터 레이크 하우스의 형태는 아래와 같습니다.

데이터 레이크 아키텍처
세션에서 직접 구축했다고 설명한 금융회사의 데이터 레이크의 아키텍처는 아래와 같다고합니다.

데이터 레이크 아키텍처는 아래 3가지로 나눠서 볼 수 있습니다.
1. 수집
2. 전환, 향상
3. 분석 시각화
데이터 레이크 수집

Amazon Kinesis : 서버리스 서비스, 예측 어려운 이벤트성 데이터 수집
Amazon MSK : 서버 기반, 지속적인 데이터 수집
Apache Flume : 이전에 레거시 환경에서 수집하던 데이터를 그대로 활용하기 위해서 사용했다고 하빈다.
데이터레이크 전환 및 향상

AWS Glue : 특수 요건 업무 및 ETL 업무에 사용한다고 합니다.
Amazon EMR : 지속적인 성능이 요구되는 영역에서 사용합니다.
Amazon SageMaker : ML 분석이 필요한경우 데이터를 SageMaker로 분석을 추가하고 데이터 향상을 가능합니다.
Hive Metastore의 Data Catalog로 AWS glue를 설정해서 메타데이터 관리를 할 수 있습니다.
데이터 레이크 분석 및 시각화

Athena, QuickSight를 통해서 데이터를 분석 및 시각화 할 수 있다고 합니다.
데이터레이크 스토리지
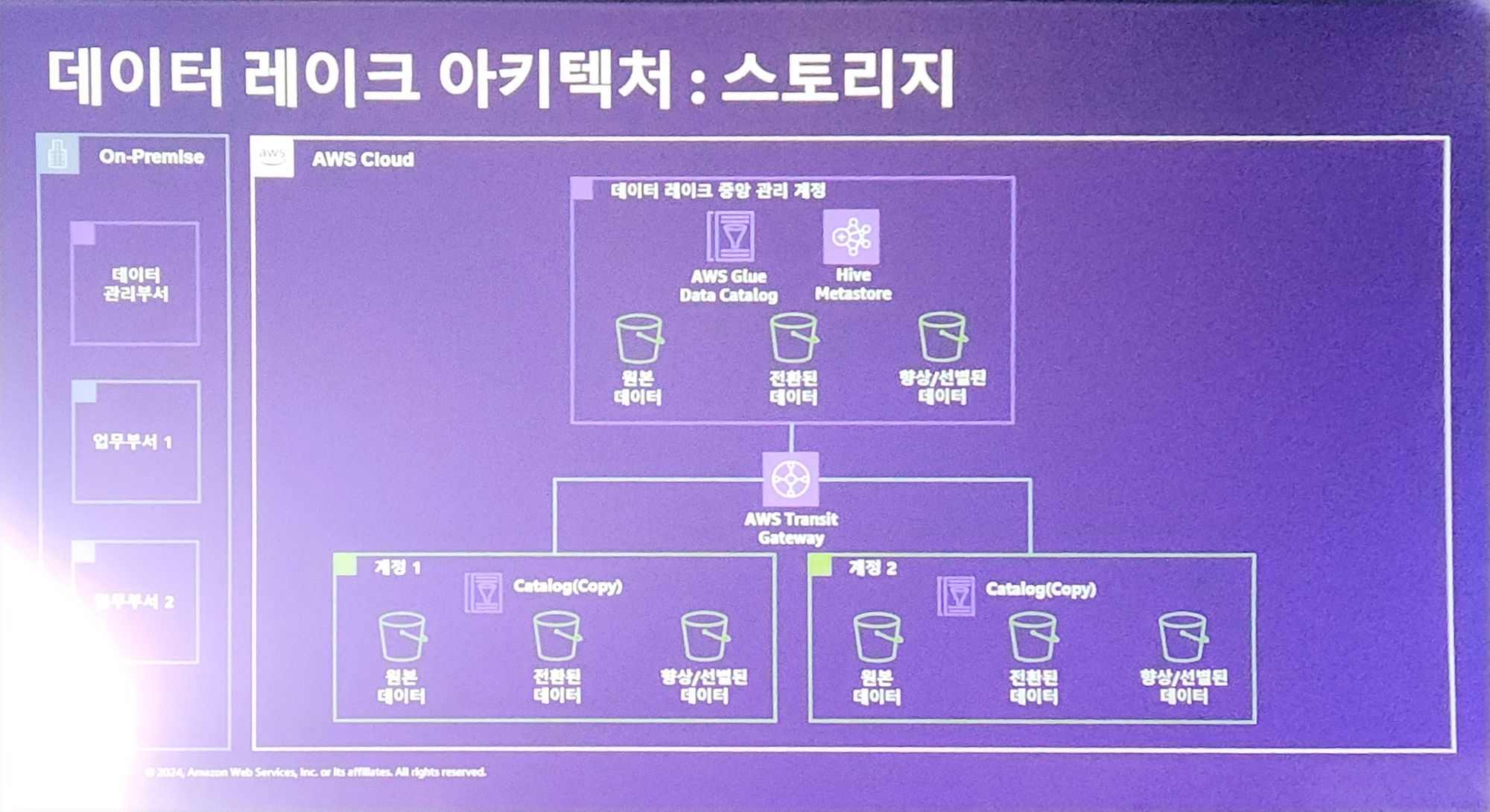
스토리지의 경우 AWS Glue , Hive Metastore 그리고 S3를 통해서 위와 같이 구성을 했다고 합니다.
해당 그림에서 금융회사의 특징이 있는데요.
일반적인 데이터레이크에서 아래와 같은 특징을 추가해야합니다.
1. Central Governance
2. Compliance
3. Security
좀 더 자세하게는 금융회사의 경우 규정 준수와 다중 계정(감사, 보안 측면에서 모니터링을 쉽게해야 하는 기능이 필요)를 지원해야한다고 합니다.
그래서 위와같이 계정에 따라서 데이터들을 활용할 수 있는 기능을 가져야하고 그런 이유로 위와같은 아키텍처를 생성했다고 합니다.
AWS Lake formation으로 데이터 레이크를 생성하기

그리고 위에서 언급한 Data lake의 직접적인 구현보다 AWS Lake Formation으로 한번에 Data Lake를 구현할 수 있다고 합니다.
2. 쿠팡의 Redshift 최적화
Amazon Redshift는 PostgreSQL 데이터베이스(DB)를 기반으로 한 완전관리형 클라우드 데이터웨어하우스 솔루션입니다.
Redshift의 클러스터 아키텍처는 아래와 같다고합니다.

Redshift 단점을 해결하기 위한 전략
Redshift의 단점을 해결하기 위한 아키텍처 최적화 전략 4가지를 소개해주셨습니다.
1. 자원 효율문제 -> Manual Workload Manager (WLM) 로 해결
모든 자원 중에서 대부분은 사용자 별로 Resource를 나눌 수 있습니다.
다만, CPU의 경우 조절이 어렵습니다.
여러 SQL이 CPU를 공유하는 순간 하나의 SQL이 그 점유를 많이 가져가면 다른 SQL은 느려질수 밖에 없는것이죠.

그래서 이런 문제를 해결하기 위해서 Workload를 여러 종류로 나눠서 우선순위를 분리하는 방법을 도입했다고합니다.
1. adhoc queue : 유저가 실행하며, 중요도가 낮은 일들
2. Batch queue : 주기적으로 실행하며, 중요도가 높음.
3. Critical (SLA) queue : 반드시 실행해야하며, 중요도가 아주 높음.
이런 Queue 분리를 통해서 Workload별로 우선순위를 관리 할 수 있었다고 합니다.
예를들면 사용자들의 요청이 많은 낮에는 adhoc queue를 조금 더 많이 할당하고, 사용자들의 요청이 별로 없는 밤(혹은 새벽)에는 adhoc queue를 줄이는 방식으로 동적으로 조절을 할 수 있게 된것이지요.
2. Concurrency 문제 -> Concurrency Scaling으로 해결
그리고 두번째로 Redshift 문제점중 하나는 하나의 Redshift에서는 동시에 50개의 SQL을 실행가능하다는 점입니다.
그 이상의 SQL은 동시에 실행할 수 없는 Concurrency 문제가 있죠.

그래서 Concurrency Scaling을 사용해서 동일한 Workload를 처리할 수 있는 Cluster를 복제해서 처리량을 늘린것입니다.
따라서, Cluster의 숫자가 y개이면 이론상 50 * y 개의 SQL을 동시에 실행할 수 있는것입니다.
그리고 Scaling 단위는 클러스터가 아니어도 되며 Queue 단위로도 Concurrency Scaling이 가능하다고 합니다.
또한, 최대 생성하는 scale cluster의 양을 제한할 수도 있어 혹시나 모를 비용문제를 막을 수 있습니다.
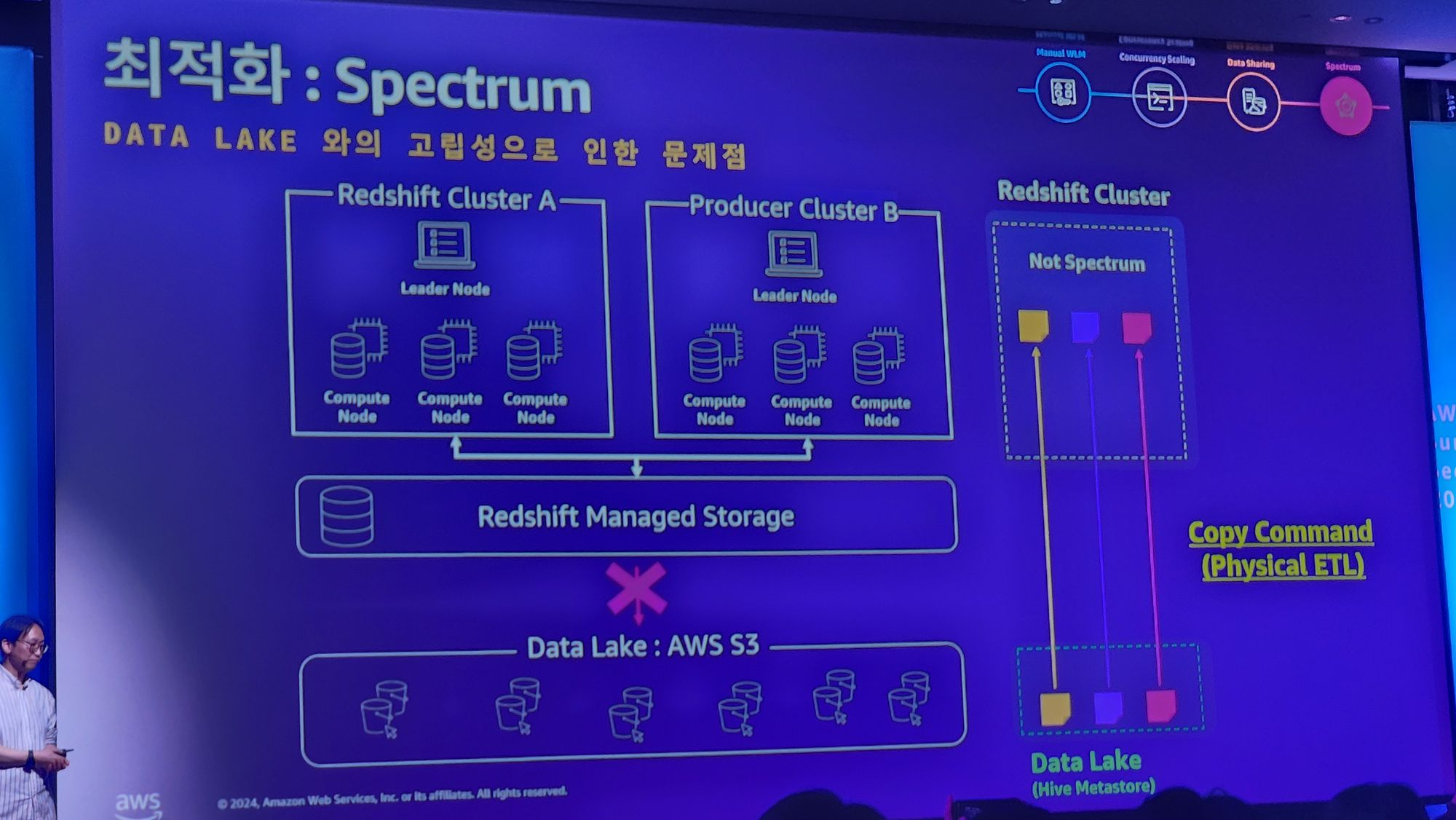
3. Data Storage 독립성문제 -> Data Sharing으로 해결
Redshift의 데이터는 독립적인 RMS (Redshift Managed Storage)에 저장된다고합니다.
그것이 장점도 있지만 단점으로는 Redshift cluster 간 데이터 공유 및 Data lake와 데이터가 공유되지 않는 문제가 생깁니다.

아래의 예를들어서 설명하자면 EDW Cluster A에 저장된 데이터는 User DW Cluster A,B,C에서 사용하려면 EDW에서 해당 데이터를 모두 복사해서 전달해야하죠.
그렇게되면 문제는 만약에 EDW Cluster A에서 해당 데이터가 변경되었을 경우, 그 변경점을 또다시 복사로 반영해야한다는 문제가 있습니다.
근데 그런 복제를 통해 데이터 싱크를 맞추는 일은 기술적으로 쉽지 않은일입니다.

그래서 쿠팡은 실제 Data를 복제하는 방식을 사용하지 않고 논리적인 복제를 이용해서 이를 해결했습니다.
아래와 같이 실제 데이터는 한곳에만 존재하고, 다른 클러스터에서는 논리적으로만 가져와서 사용하는 방식인것이죠.
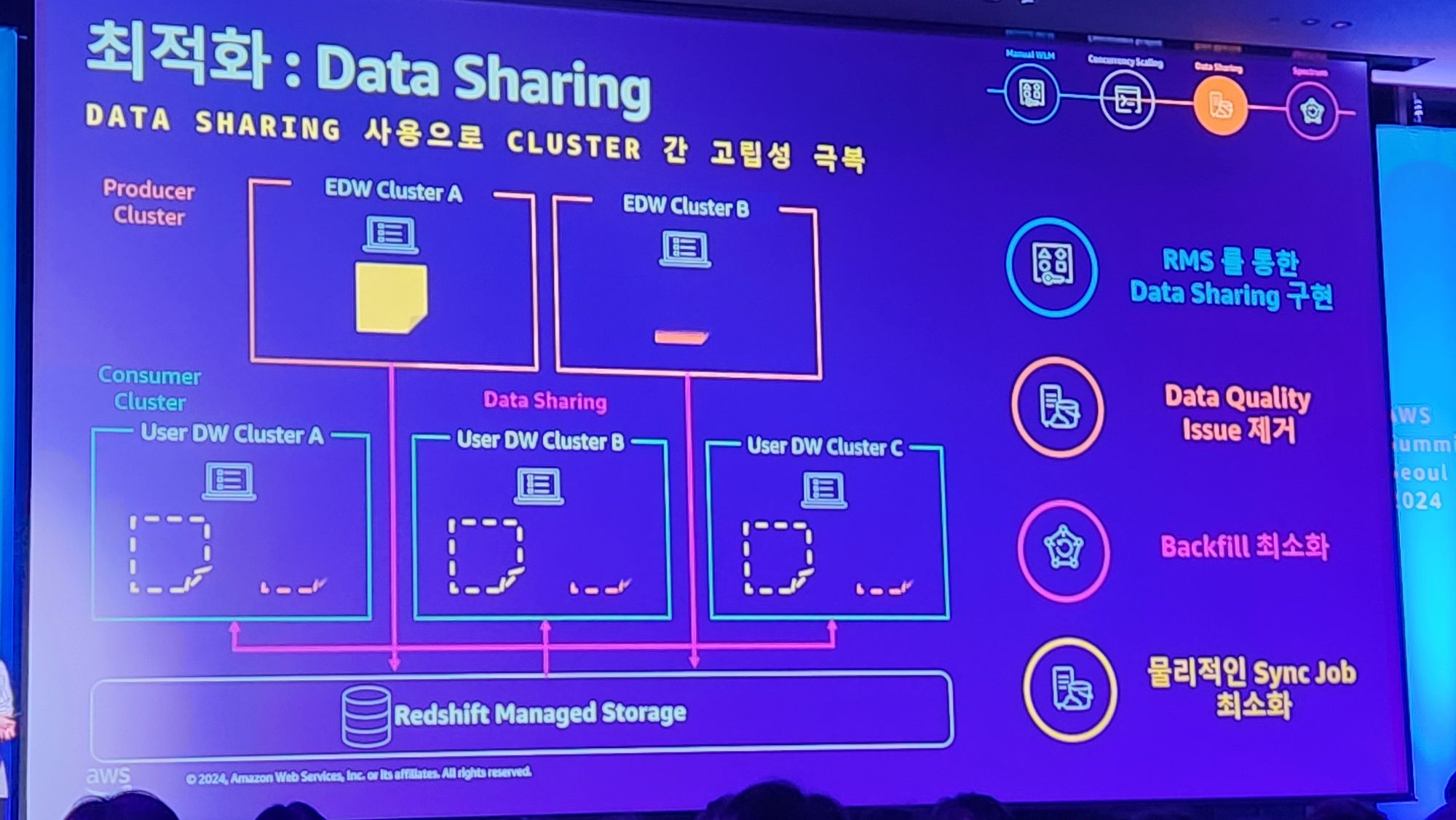
위와 같은 방법을 통해서 물리적인 데이터 Sync를 없애고 논리적 Sync로 해결하여
아래와 같은 예시 케이스에서 7번 복제를 해야하는 문제를 0번 데이터 복제를 하여 해결했음을 보여줍니다.
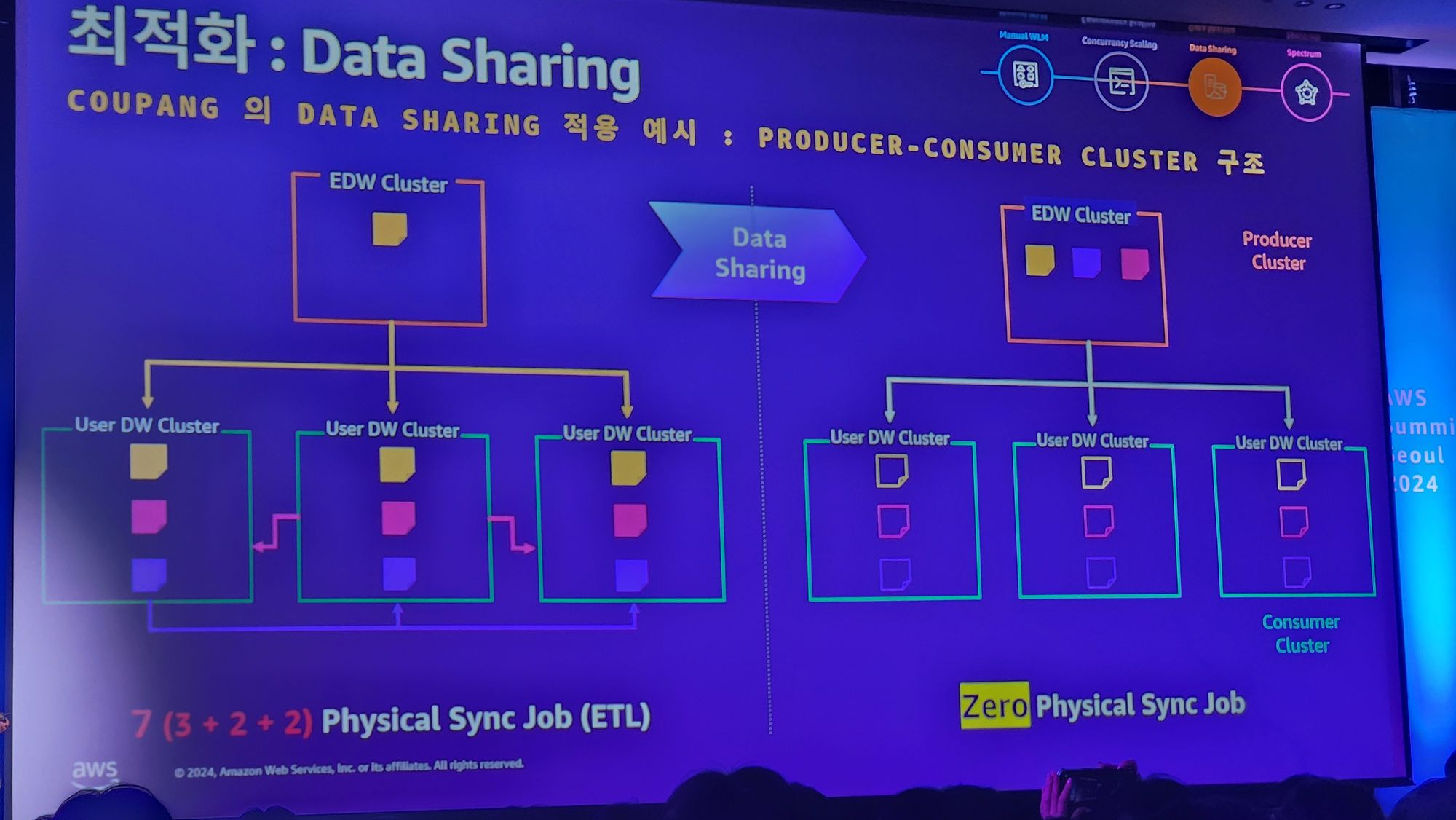
4. 데이터 레이크와의 고립성 -> hive database의 spectrum으로 해결
3번 문제의 첫번째 그림에서도 봤듯 데이터 레이크와도 고립되는 문제가 있었는데요.
이는 Spectrum이라는것으로 해결했습니다.
이는 3번과 비슷한 방식의 해결방법이며, 그것은 Hive Metastore가 지원하는 기능입니다.
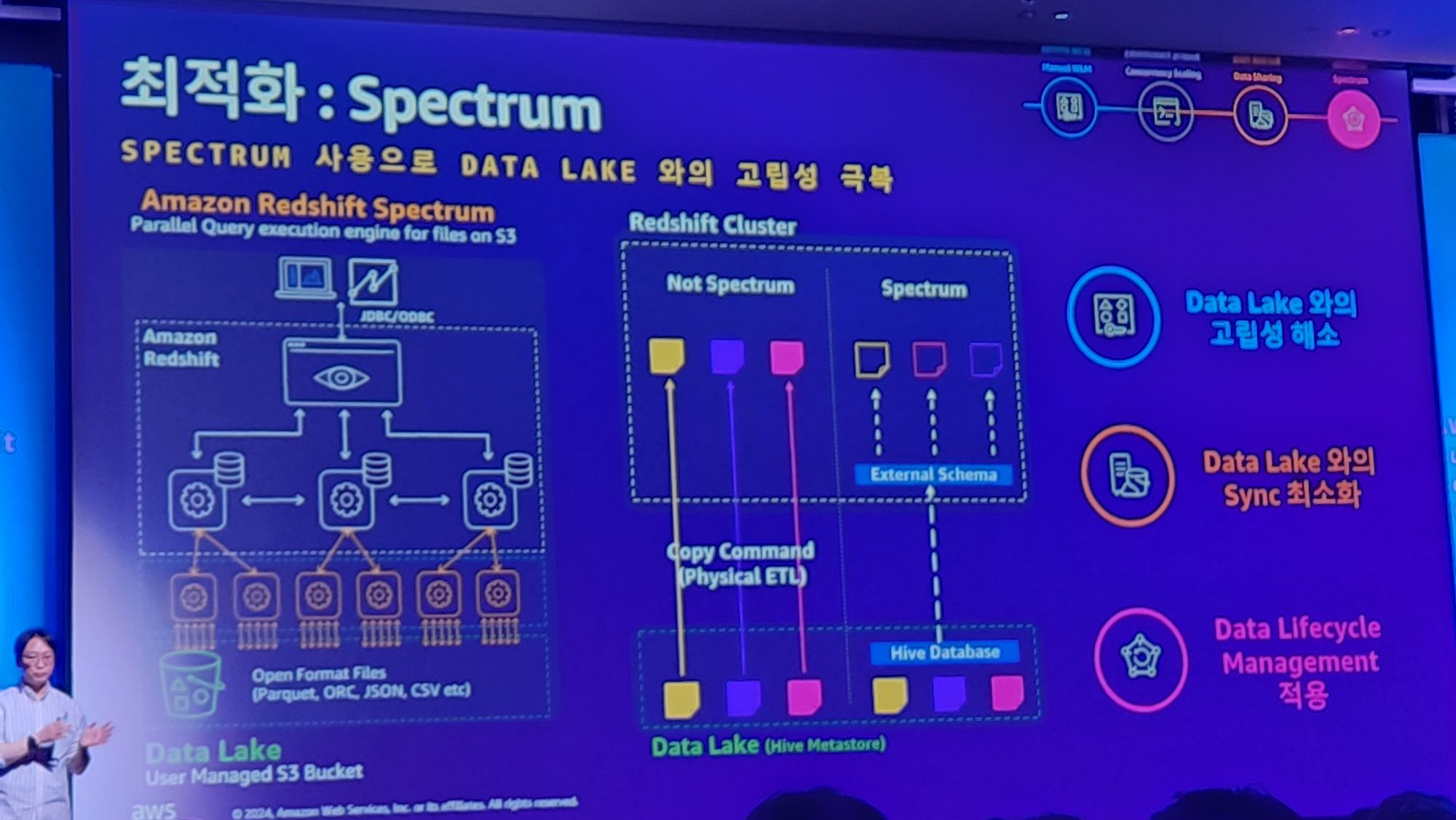
이를 통해서
1. Data Lake와의 고립성 해소
2. Data Lake와의 Sync 최소화
3. Data Lifecycle Management를 적용을 할 수 있었다고합니다.
부록
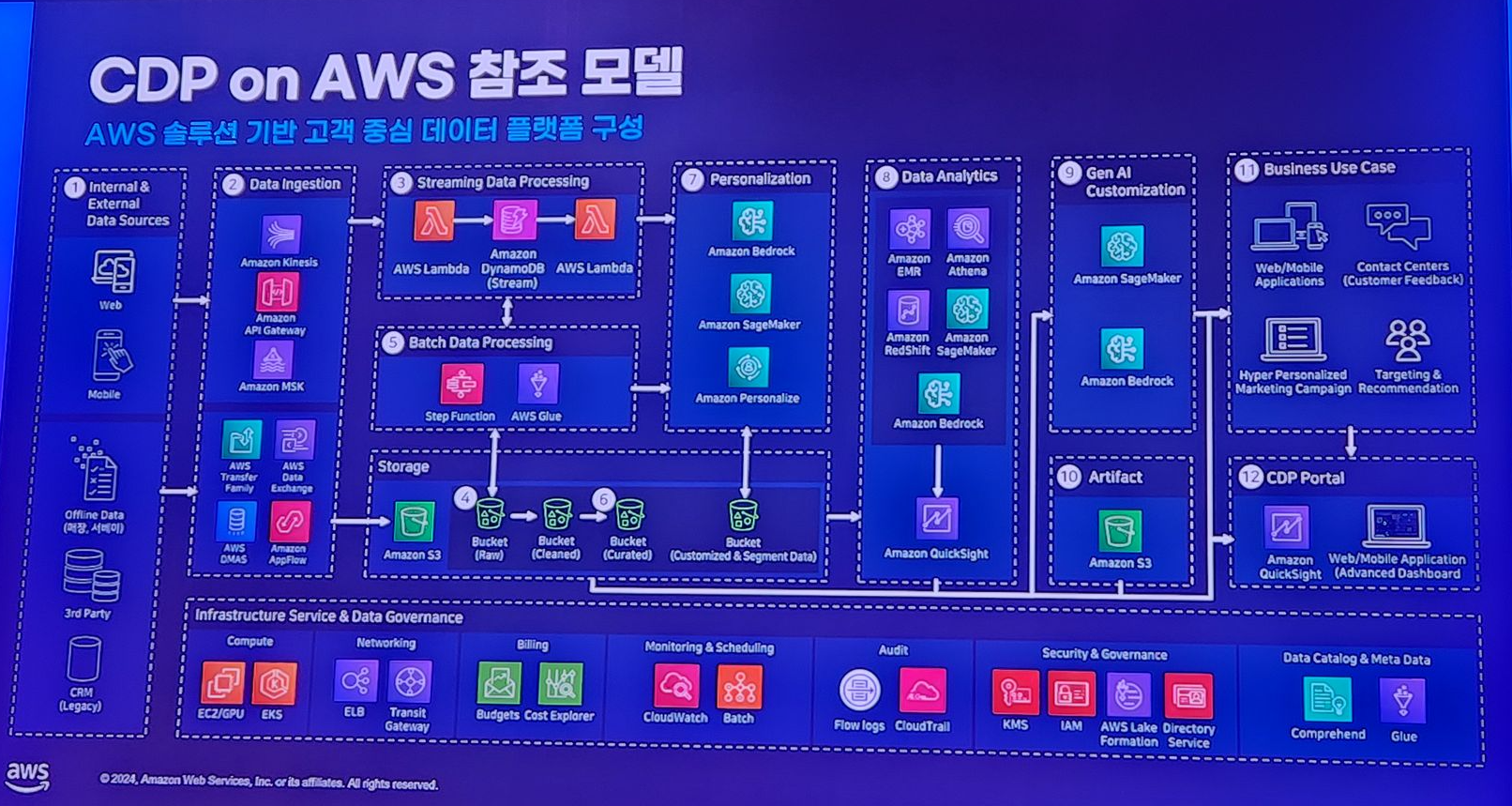
생성형 AI 시대의 Data platform 구축방법에 대한 세션이 있었는데 이를 요약한 아키텍처만 아래 사진으로 가져왔습니다.
'개발 트렌드 포스팅 > 2024 AWS Summit Seoul' 카테고리의 다른 글
| AWS Summit Seoul 2024 - AWS 스토리지로 AI/ML 워크로드 가속화 (0) | 2024.05.24 |
|---|
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.
