

이번 AWS Summit Seoul 2024는 주로 AI/ML 그리고 LLM에 대한 내용이 메인을 이루고 있었습니다.
그 중에서 Storage와 관련된 세션이 저의 주 관심사였습니다.
"AWS스토리지로 AI/ML 워크로드 가속화" 라는 세션에 참가했고 AI/ML의 인프라 관점에서의 인사이트를 얻을 수 있었어서 공유드립니다.
ML 관점에서 스토리지의 중요 표인트
최근에 AI에 대한 관심이 많아지면서 용어를 혼용해서 쓰는 경우가 많았어서 먼저 각 용어에 대해서 먼저 정의를 했다고합니다.
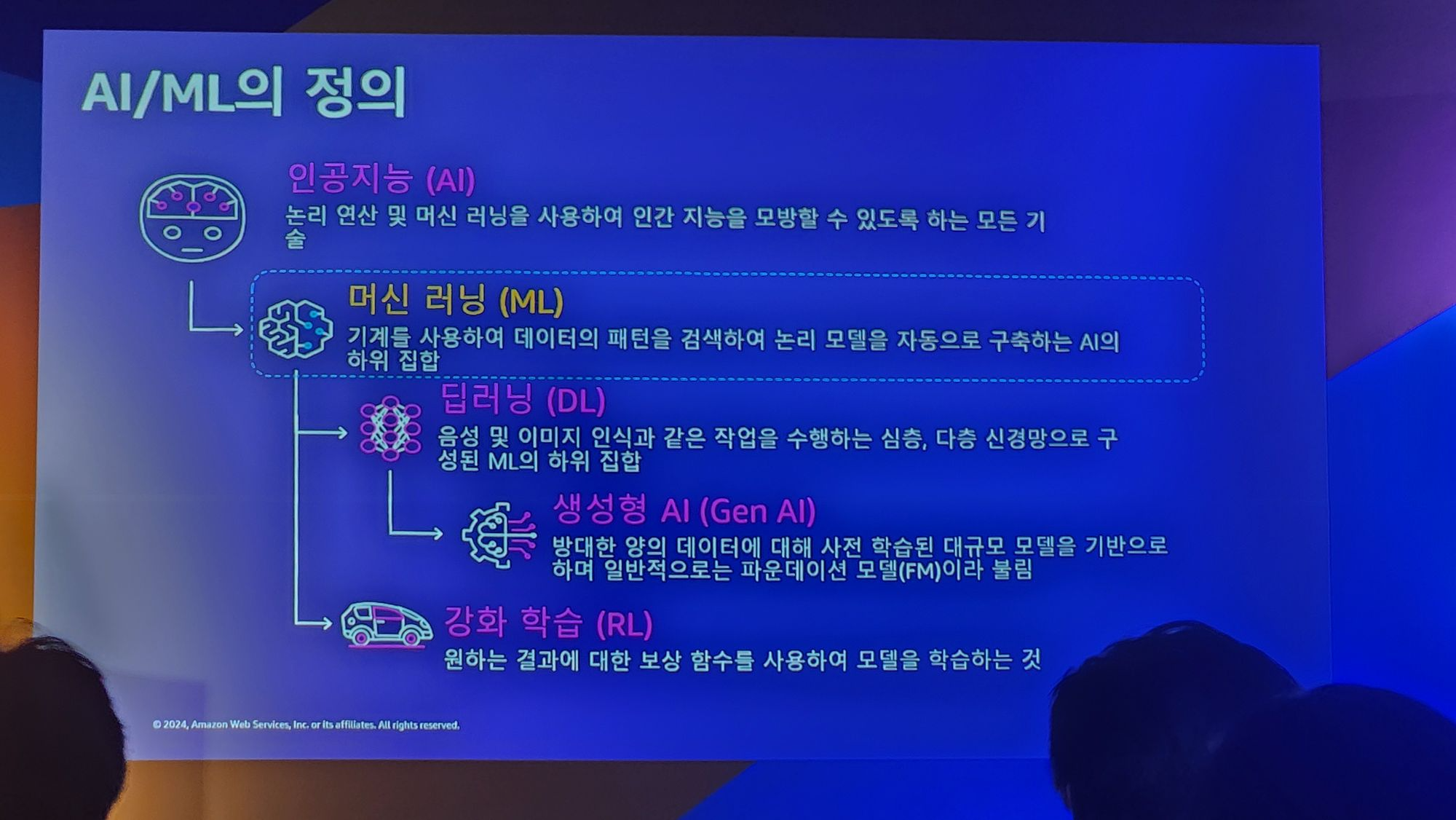
그 중 ML을 어떻게 구축하는지를 아래의 장표에서 정리를해주었습니다.
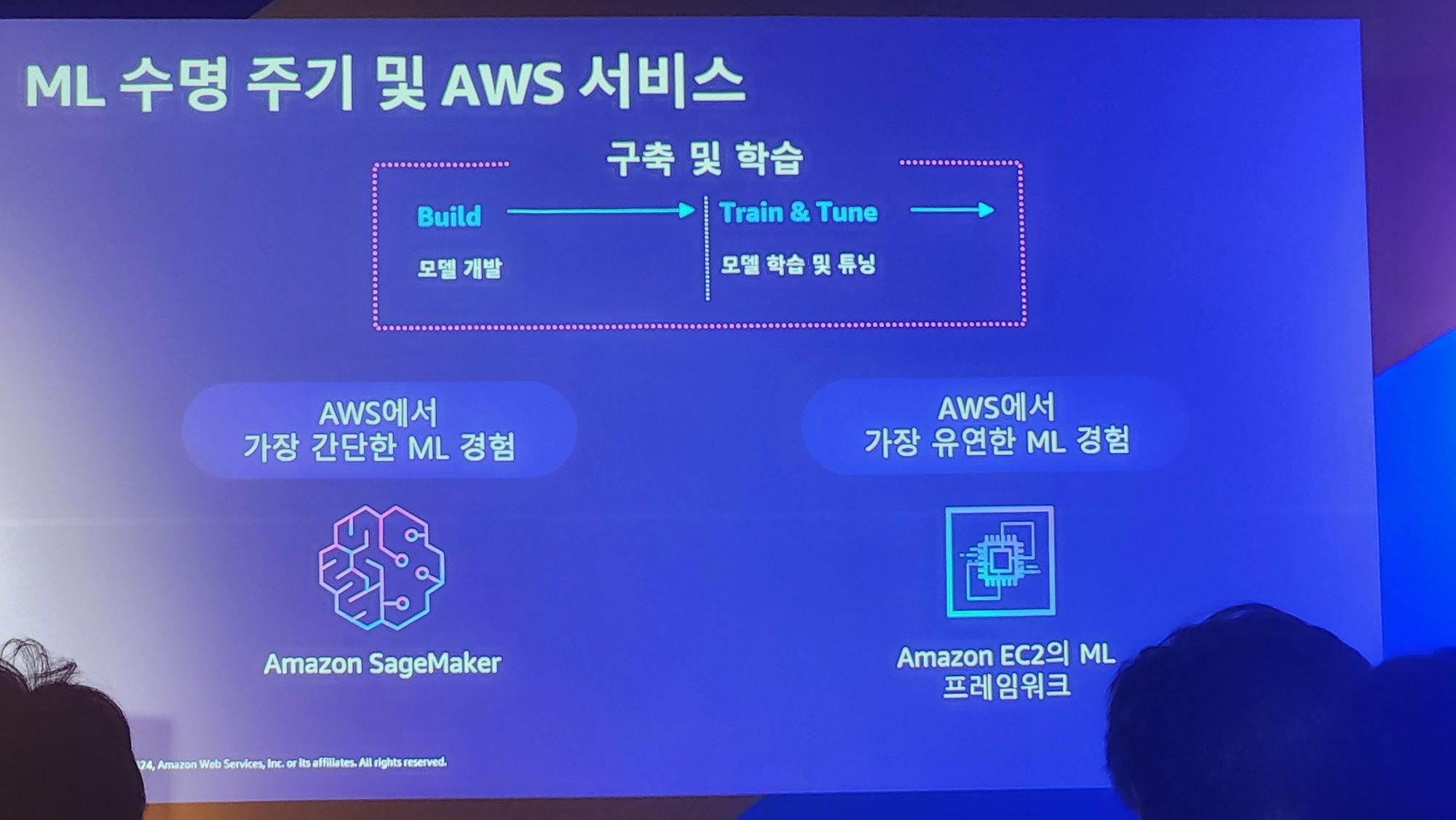
핵심은
1. Build : ML 모델을 개발한다.
2. Train & Tune : 개발한 모델을 학습시키고 튜닝한다.
라는 과정을 거친다는것입니다.
Amazon SageMaker와 EC2의 프레임 워크는 AWS 인프라에서 이 과정을 최대한 쉽게 할 수 있도록 도와준다는것입니다.
본 포스트의 "참고" 세션을 확인하여 조금 더 자세한 정보를 얻을 수 있습니다.
그러면 여기서 스토리지는 어떤 역할을 하고, 제약사항은 무엇인지 확인해 볼 필요가 있습니다.
AI에서의 가장 큰 이슈는 바로 모델을 학습시키는 비용이라고 볼 수있습니다.
그런데 그 모델을 학습시키는 비용은 컴퓨팅 성능과 직결됩니다.
그리고 GPU의 가격이 천정부지로 올라가버린 지금 GPU를 최대한 적게 쓰고 좋은 모델을 만들어 내는게 핵심이라고 볼 수 있죠.
그러려면, GPU가 사용하는 다른 자원이 GPU를 사용하는데에 병목이 되면 안됩니다.
그래서 스토리지 관점에서 ML의 첫번째 중요 포인트는 데이터 로딩입니다.
1. 데이터로딩

스토리지와 GPU 관점에서 ML의 학습순서는 다음과 같습니다.
1. 스토리지로 데이터를 로딩하고
2. 해당 데이터를 통해 GPU로 모델을 학습시킵니다.
스토리지의 성능이 낮아 데이터를 로딩하는데 시간이 많이 걸리게 되면 같은 비용으로 GPU를 활용할 수 있는 시간이 줄어들죠.
그러므로 최고의 스토리지는 아니더라도 GPU를 사용하는데 병목을 일으키지 않는 스토리지를 사용하는것은 중요합니다.
ML의 경우에는 전통적인 어플리케이션 보다는 HPC 어플리케이션에 가깝습니다.
따라서, 아래와 같이 스토리지 성능/용량을 늘리고 GPU를 줄이는 방식이 더 적합할 수 있습니다.
| 앱의 스토리지 특징 | |
| 전통적인 앱 | Storage 용량을 최적화하고 줄여서 가격을 줄입니다. |
| HPC 앱 | 전체 비용을 줄여야합니다. (e.g. 스토리지를 늘리고 GPU를 줄여서 가격을 줄일 수도 있음) |
이번에는 데이터 로딩 성능에 영향을 미치는 요소를 확인해보겠습니다.

1. 데이터의 크기와 파일 수
2. 개별 파일 크기 및 유형
3. 데이터 수집
4. 액세스 패턴
등이 있습니다.
ML에서는 위와 같은 특징중에 워크로드가 어떤 특징이 있냐에 따라서 SSD나 HDD중에 잘 골라서 사용해야합니다.
스토리지 관점에서 ML의 또 다른 중요 포인트는 체크포인트입니다.
2. 체크포인트
체크포인트란 현재까지 학습된 모델을 스토리지에 저장해 두는것을 의미합니다.
최근의 ML 모델의 크기는 용량이 계속 커지는 추세였습니다.
그런 모델을 한번에 학습을 하려고하면 인프라를 최소한으로 쓸 수 있다는 장점이 있습니다.
하지만! 만약에 학습 중간에 인프라의 오류 혹은 고장에 인해서 학습이 실패한다면, 그때까지의 학습 데이터는 다 날아가게되고 이전과 동일한 시간을 추가로 들여서 또다시 학습을 해야합니다.
그러면 그 시간만큼이 또 추가 비용으로 발생하게되죠.
이런 비용을 최소화 하기 위해서 체크포인트를 도입해서 해결 하고 있습니다.

체크포인트를 통해 인프라 고장으로 인해 모든 ML 학습을 처음부터 다시 해야하는 문제는 해결했습니다.
그럼에도 불구하고 체크포인트를 하는 시간은 GPU 및 컴퓨팅 리소스는 대기 하는 시간이므로 학습시간의 낭비라고 볼 수있고 이것도 마찬가지로 기존에 비해 적더라도 비용입니다.
위의 예시에서 체크포인트 2를 진행 중에 문제가 생기는 경우를 가정하면
GPU를 낭비하는시간 = 체크포인트 1 저장 시간 + 체크포인트 2 저장시간 + 체크포인트 1을 로딩하는시간
이라고 볼 수 있습니다.
여기서 좋은 스토리지를 사용해서 체크포인트 시간을 줄이고, GPU 시간을 최적화 하는것이 최근 ML의 트렌드인것같습니다.
그리고 AWS에서 AI/ML 학습 비용을 최적화 하는 방법을 설명했습니다.
AWS의 인프라에 관심이 없으신 분들은 여기까지만 읽으셔도 좋을것 같습니다.
AWS 스토리지로 ML 학습 비용과 성능 최적화
AWS 스토리지는 아래 두 가지 기능을 ML 스토리지의 핵심으로 지원하고있다고합니.

1. 리프트 & 시프트 파일 시스템
2. Amazon S3 데이터 레이크입니다.
리프트 & 시프트 파일 시스템
리프트 & 시프트 란 기존 On-premise로 사용하던 시스템을 클라우드로 데이터를 옮기는것을 의미한다고합니다.
고객들이 주로 원한게 (혹은 원한다고 예상했던게?) on-premise와 완전히 동일하게 사용하고 싶다 라고합니다.
그래서 AWS에서는 AWS FSx라는 서비스를 만들었죠.
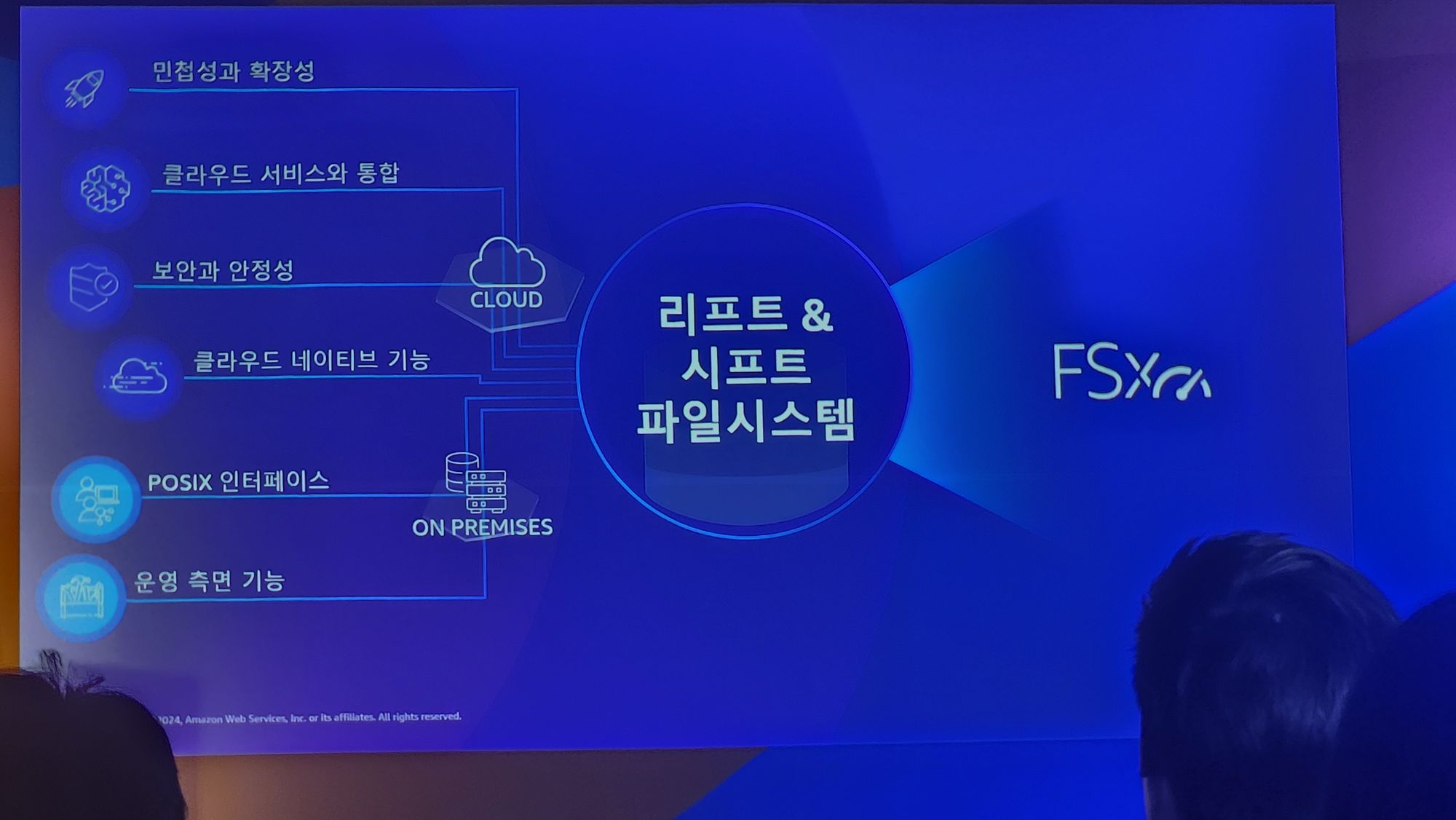
ML학습에서는 대부분 Lustre를 사용하니 이를 AWS에서도 동일하게 사용하고 싶을것입니다.
Amazon FSx for Lustre 파일 시스템이 그래서 만들어졌다고 합니다.

1. 대부분의 ML 어플리케이션 (파이토치, AWS Sage Maker 등등)
2. 직관적이고 일관된 데이터 엑세스 ( 파일접근 인터페이스, Posix 권한이 기존 사용과 동일, 데이터 일관성)
3. 빠르고 Scalable한 랜덤 데이터 엑세스의 장점이 있다고합니다.

파일 시스템 측면에서 비용 최적화 방법
기존에는 불필요한 용량도 비용으로 사용했어야 했다고합니다.
이것을 자동으로 조절 가능하게 변경했다고합니다. (어떻게 했는지는 정확하게 모르겠습니다 ㅎㅎ;)

그리고 Lustre와 S3를 사용해서 데이터 로딩을 최적화했다고 합니다.

단순 파일 모드만 사용하면 데이터 다운로드 시간 + 모델 학습 시간이 많이 들지만,
S3 + FSx로 학습시간을 크게 줄일 수 있다고 홍보하고있습니다.
설명으로는 Lustre가 S3안에있으면 데이터 세트 다운로드가 한번이상 필요없다고 설명했습니다.
의문1 : 지연된 로드 데이터가 정확히 뭘 의미하는지?
의문 2 : 캐시데이터는 어떤것을 의미하는지?
저는 위와 같은 의문사항이 생겼었는데요.
아래와 같이 정리할 수 있을것 같습니다.
1. SageMaker 파일모드
SageMaker라는 ML 모델 학습 인스턴스에 파일을 직접 로컬 파일시스템에 다운로드 받아서 사용하는 방식입니다.
따라서, 원하는 모델을 학습하기 위해서는 모든 훈련용 데이터를 먼저 다 받아놓고 학습을 시작해야하는것이죠.
그래서 데이터를 전부 받고 난 이후부터 학습을 시작할 수 있습니다.
인프라 사용 : SageMaker (ML 학습), S3 (학습용 데이터 다운로드 및 학습 모델 저장)
총 필요 시간 = 데이터 셋 다운로드 시간 + 모델 학습시간
2. S3 + FSx - 첫 번째 실행시
이 경우는 SageMaker + FSx lustre + S3를 가정합니다.
Lazy load를 사용하게 되면 모든 데이터를 미리 다 다운로드하고 시작하지 않습니다.
처음 메타데이터만 받아놓고 실제 데이터는 사용할때 다운로드합니다.
그러므로 첫번째 배치 학습 데이터만 받으면 바로 학습을 시작할 수 있습니다.
인프라 사용 : SageMaker (ML 학습), FSx for lustre (파일 시스템을 SageMaker에 마운트), S3 (학습 데이터 다운로드 via FSx용, 학습 모델 저장)
총 필요 시간 = 첫번째 학습 배치 데이터 불러오는 시간 + 모델 학습 시간
3. S3 + FSx - 두 번째 실행부터 N번째 까지
이 경우 2번과 동일하며 "캐시데이터 = 배치 데이터를 이미 메모리에 올려 둔 상태" 를 가정하는듯합니다.
따라서, 이미 학습 배치데이터가 메모리에 올라가있으니 학습을 바로 시작할 수 있습니다.
동일 데이터를 활용해 학습하는 경우가 아주 많은 지는 모르겠으나, 모델 변경에 따라서 동일 데이터를 활용할 수 도 있다는 생각이 들긴합니다.
인프라 사용 : SageMaker (ML 학습), FSx for lustre (파일 시스템을 SageMaker에 마운트), S3 (학습 데이터 다운로드 via FSx용, 학습 모델 저장)
총 필요 시간 = 모델 학습 시간
체크포인트도 아래와 같이 티어링을 할 수 있다고 합니다.

Cloud Native 에서 AI/ML 비용 최적화 - Amazon S3 데이터레이크

S3를 ML의 데이터 레이크로 사용함으로 최적화 하는것을 의미하는것 같습니다.
세션에서 하나의 예시를 들어주었는데요
동일 데이터에 대해서
1. S3 데이터를 모두 로컬에 다운받아서 진행하는 방법은 28분 소모가 되었다고하는 반면
2. S3 데이터를 데이터 스트리밍해서 다운로드 하는경우 5분 (80% 시간 감소) 가 되었다고합니다.
(여기서의 데이터 스트리밍의 위에서의 지연된 데이터 로딩과 같은 개념이라고 보면 될듯합니다.)
추가로 S3 Express One zone 서비스 출시를 언급했는데요. 관련 내용을 아래와 같이 정리했습니다.
1. S3 Express One Zone은 계산 집약적 워크로드를 대상으로하는 서비스라고합니다. (주로 AIML용 타겟인듯 합니다)
2. One Zone으로 설계 된 이유는 물리적으로 컴퓨팅 리소스와 스토리지 리소스를 한곳에 모아서 10ms 지연시간을 지원하기 위함이라고 하네요.
3. 디렉토리 버킷을 쓴다고합니다.
이를 통해서 버킷명의 프리픽스당 TPS 제한이 없다고합니다.
(참고 - 디렉터리 버킷 - Amazon Simple Storage Service)
혹시나 OneZone 고장에 대비해서 다른 zone의 S3 standard 등의 서비스와 같이 쓰면 좋다고 합니다.
그리고 S3 기능 중 mountpoint라는것을 언급했는데요.
S3를 로컬 파일 시스템처럼 쓸 수 있게 지원하는 기능이라고합니다.
Mountpoint for Amazon S3
로컬 파일 시스템 API 호출을 S3 객체의 REST API 호출로 자동 변환하며, 한 번에 여러 클라이언트에서 대용량 객체에 대한 높은 읽기 처리량이 필요한 애플리케이션에 최적화되어 있습니다.
기존 파일에 대한 순차 및 임의 읽기 작업을 지원하고 한 번에 단일 클라이언트에서 새 개체를 순차적으로 씁니다. 대량의 S3 데이터를 병렬로 읽고 생성하지만 기존 객체의 중간에 쓸 수 있는 기능이 필요하지 않은 대규모 분석 애플리케이션에 적합합니다.
즉, 파일 인터페이스를 사용하는 응용 프로그램에 매우 적합합니다.
이 기능을 사용하는 이유는 Lustre가 파일시스템이기에 lustre를 그대로 활용하려면 S3의 데이터들을 filesystem에 저장해야함으로 보입니다.

이를 통해서 모델의 더 빠른 학습을 지원한다고합니다.
그리고 Mountpoint for S3는 캐싱을 지원하여 같은 데이터를 추가 학습시킬때 더 빠른 속도를 보여줄 수 있다고합니다.

Mountpoint for Amazon S3, 반복되는 데이터 액세스 최적화
Mountpoint for Amazon S3는 이제 반복되는 데이터 액세스를 위해 Amazon EC2 인스턴스 스토리지, 인스턴스 메모리 또는 Amazon EBS 볼륨에 데이터를 캐시할 수 있습니다. 이렇게 하면 동일한 데이터를 여러
aws.amazon.com
그리고 발표자분께서 체크포인트시에 로컬 파일 시스템에 체크포인트를 저장하는것 보다 S3에 저장하는것이 빠르다고 했습니다.
사실 별도 설명없이 한문장만 들었던것같아서 말도 안된다고 생각해서 잘못들은줄 알았는데요.
이와 관련된 포스트를 한번 찾아봤습니다.
AWS Delivers 'Lightning' Fast LLM Checkpointing for PyTorch
AWS customers who are training large language models (LLMs) will be able to complete their model checkpoints up to 40% faster thanks to improvements AWS
www.datanami.com
포스트 안에는 이런 문장이 있었습니다.
“Local SSD is obviously pretty darn fast,” he continued. “So they came back and said ‘Andy, check out our results. We are faster writing checkpoints to S3 than we are writing to the local SSD.’ And I was like, guys, I call BS on this. There’s no way you’re beating the local SSD for these checkpoints!”
요약하자면 로컬SSD보다 S3에 저장하는게 빠른 테스트 결과가 있어서 믿지 않았다.
의문 3. 체크포인트시 로컬 파일 시스템 보다 S3가 더 빠르다고 말할 수 있는 이유가 무엇인지?
포스트에는 아래와 같이 표현을 했습니다.
핵심은 SSD가 PCIe 레인에 성능이 제약되어있다는 것입니다.
NIC 보다 SSD에 대한 PCIe 레인이 더 적습니다.
따라서, S3에 대한 연결을 병렬화 함으로 써 S3는 실제로 쓰기중이던 이 로컬 SSD보다 호스트의 PCIe 버스에서 처리량이 더 높았습니다.
병렬화를 통해서 S3에 저장하는것이 로컬 SSD에 Checkpoint 하는것보다 빠르게 되었다라고 요약할 수 있겠습니다.
좀 더 찾아보니 실제로 AWS가 공시한 발표가 있었습니다.
PyTorch용 Amazon S3 커넥터, 이제 PyTorch Lightning을 통한 체크포인트 작성 지원
PyTorch용 Amazon S3 커넥터, 이제 PyTorch Lightning을 통한 체크포인트 작성 지원
이제 PyTorch용 Amazon S3 커넥터는 PyTorch Lightning 모델 체크포인트를 Amazon S3에 직접 저장할 수 있도록 지원하여 기계 학습 훈련 작업의 비용과 성능을 개선합니다. PyTorch Lightning은 PyTorch를 사용하는
aws.amazon.com
이제 PyTorch용 Amazon S3 커넥터는 PyTorch Lightning 모델 체크포인트를 Amazon S3에 직접 저장할 수 있도록 지원하여 기계 학습 훈련 작업의 비용과 성능을 개선합니다.
...
PyTorch용 Amazon S3 커넥터는 S3 요청을 자동으로 최적화하여 훈련 워크로드의 데이터 로드 및 체크포인트 성능을 개선합니다.
PyTorch용 Amazon S3 커넥터를 사용하면 PyTorch Lightning 모델 체크포인트를 저장하는 것이 Amazon EC2 인스턴스 스토리지에 작성하는 것보다 최대 40% 더 빨라집니다.
참고
Amazon SageMaker

Amazon EC2의 ML 프레임워크

A comparative analysis of Mountpoint for S3, S3FS and Goofys
In the realm of cloud computing, Amazon Web Services (AWS) has revolutionized how organizations manage and store their data. Amazon S3…
medium.com
Optimize_HPC_workload_storage_using_Amazon_FSx_for_Lustre_STG348.pdf (awsstatic.com)
Mountpoint for S3를 이용한 S3 마운트
AWS 사용자들은 S3fs, goofys 등을 이용해서 S3를 마운트해서 사용했다. 2023년 8월에 AWS는 Mountpoint for Amazon S3를 정식으로 출시함으로써, 엔터프라이즈 환경에서 안정적으로 S3를 마운트해서 사용할 수
www.joinc.co.kr
'개발 트렌드 포스팅 > 2024 AWS Summit Seoul' 카테고리의 다른 글
| AWS Seoul Summit 2024 - 스토리지 관련 세미나 요약 모음 (7) | 2024.05.25 |
|---|
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.
