Attention을 이해하기 위해서는 Encoder-decoder 아키텍처에 대해서 이해를 해야합니다.
아래는 이미지를 Input, Output으로 하는 Encoder-Decoder 아키텍처의 예시입니다.
이미지에 색상을 부여하는 Encoder-decoder 아키텍처의 예시입니다.
간략히 요약하자면 아래와 같은 구조로 요약할 수 있습니다.
Encoder-Decoder 아키텍처
Encoder Decoder 아키텍처는 Deep Learning 의 다양한 분야에서 활용되는 아키텍처입니다.
아래와 같은 모델들의 기반 모델로 사용됩ㄴ디ㅏ.
Auto Encoder
입력 데이터 x를 받아서 압축하고 다시 원래의 데이터 y로 재구성 하는 모델입니다.
U-net
이미지 분할(Segmentation)을 위해 Encoder가 공간 정보를 압축하고, Decoder가 이 압축된 정보를 기반으로 원래 이미지 크기의 마스크를 생성합니다.
Sequence-to-Sequence 모델 및 Transformer
Encoder가 입력 시퀀스를 처리하여 의미적 표현을 추출하면, Decoder는 이 표현을 바탕으로 다른 형태의 시퀀스를 출력합니다 (예: 기계 번역, 챗봇 응답 생성).
Transformer는 Encoder와 Decoder에 attention 메커니즘을 활용하여 입력과 출력 사이의 관계를 보다 정교하게 모델링합니다.
아키텍처 내에서 각각의 역할을 요약하면 아래와 같습니다.
Encoder - Input을 요약하는 기능을 합니다.
code/latent h - Input을 효율적으로 표현합니다.
Decoder - Output을 생성하는 역할을 합니다. (Gen AI에서 아주 중요한 역할을 하죠)
그 다음은 Language Modeling의 개념입니다.
Language Modeling
Language Model이란
의미있는 단어/문장을 예측하고 만들어내기(generate) 위한 learning model입니다.
e.g. "next word predictor"
Language generation은 autoregressive decoding으로 동작합니다.
autoregressive decoding은 아래와 같이
직전의 입력(input)을 가지고 다음 단어를 출력(output)하는 것을 의미합니다.
아래가 autoregressive하게 동작하는 decoder의 예시입니다.
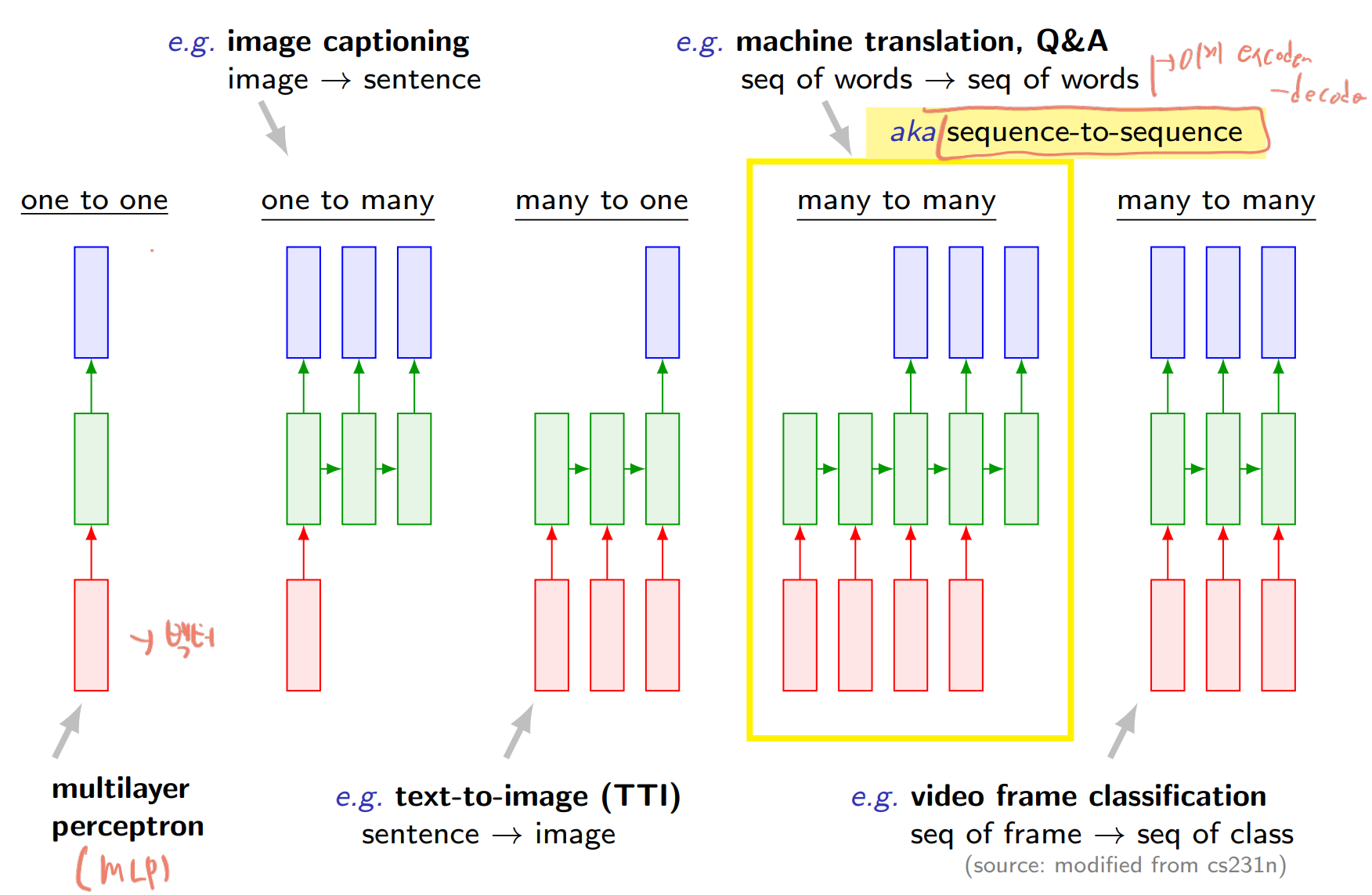
그리고 다음으로 알아야 할 배경지식은 RNN 모델의 개념 중 시퀀스 데이터의 처리 능력입니다.
RNN의 시퀀스 형태의 데이터 처리 능력
RNN은 아래와 같이 4가지 형태의 입력/출력을 지원할 수 있습니다.
one to one
one to many
many to one
many to many
RNN의 Sequence 처리 능력들
이 중에서 many to many의 개념을 조금 더 정교하게 활용하는것이 Encoder-Decoder 아키텍처 인것입니다.
그것을 흔히 Sequence to Sequence 라고 불리는데 이를 Encoder-Decoder 아키텍처로 부릅니다.
Sequence to Sequence 구조를 채택하는 Encoder-Decoder 아키텍처
Sequence to Sequence는 조금 더 분해를 해보면 Seq2Seq = (many to one) + (one to many) 의 구조와 같습니다.
Many to One : 이 부분이 Encoder에 해당하며, input sequence를 하나의 vector로 만듭니다.
One to Many : 이 부분이 Decoder에 해당하며, 하나의 vector를 다시 output sequence로 만듭니다.
Context : 바로 위에서 언급한 input sequence를 요약한 "하나의 vector" 를 Context라고 지칭하며 추후 배울 cross attention과 연관이 있습니다
여기까지가 Attention을 이해하기 위한 기초 지식이었습니다.
이제는 본격적으로 Attention을 배워보도록 하겠습니다.
교수님의 팁 1 최신 AI 트렌드에 대해서 질문을 주시는 분들이 많다고 합니다. AI 학계의 트렌드를 빠르게 추적하는 하나의 방법으로 AI 분야에서 TOP 학회의 Tutorial을 보면 좋다고 합니다. Attention 또한 그 중요한 트렌드 중 하나였기에, 2019년의 ICML이라는 학회의 Tutorial에는 Attention이 Tutorial로 나와있었습니다.
Attention Mechanism
우선을 이해 하기 쉽게 Attention의 의미를 간단하게 파악해보려고 합니다.
Introduction
사전적으로 Attention의 의미는 "관심, 집중" 의 의미입니다.
NLP에서의 Attention은 특정 단어들이 서로 어느정도로 관심을 많이 가지고 있냐입니다.
위의 예시는 독일어(위)를 영어(아래)로 바꾸는 NLP입니다.
보라색 선의 진한 정도가 Attention의 정도입니다.
네모박스에서 강한 Attention을 가지는것들을 표현하자면 아래와 같습니다.
독일어 zone -> 영어 Area
독일어 europeenne -> 영어European
독일어 economique -> 영어 Economic
그리고 강한 Attention이 아니더라도 모든 단어들은 작게나마 서로 attention을 가지고 있습니다.
컴퓨터 비전에서도 Attention이 있을 수 있는데 아래와 같습니다.
왼쪽 사진이 Attention을 하지 않은것, 오른쪽 사진이 밑줄친 부분을 attention 하는것입니다.
각 사진에서 Frisbee, dog, stop sign에 하얗게 표시가 되어있죠 이런것들을 컴퓨터 비전에서의 attention이라고 볼 수 있습니다.
Seq-To-Seq을 개선한 attention
기존 RNN을 활용한 Encoder-Decoder 아키텍처의 문제점이 있었는데요.
그것은 바로 문장의 길이가 길어지면 모델의 성능이 극적으로 떨어진다는 점이었습니다.
그 이유는 Context 의 차원(dimension)이 긴 Sequence를 이해하기에 충분하지 않았다는 것입니다.
“Neural machine translation by jointly learning to align and translate"이라는 2014년 논문은 어느정도의 Context가 필요한지를 측정 해 보려고 했습니다.
RNN encoder-decoder 모델 사용시에 데이터 양의 개수(50 vs 30)와 Attention 사용 유무와 Sequence 길이에 따른 성능의 차이
빨간색 네모는 Attention을 사용한 모델, 파란색은 Attention을 사용하지 않은 모델입니다. 결과를 요약하자면 아래와 같습니다.
Attention을 사용한 모델이 더 좋다.
Context vector를 크게하고 데이터의 양이 많을수록 좋다. (기존에는 fixed size vector를 많이 쓴것 같습니다.)
이 논문의 결과가 기존의 Encoder-Decoder 아키텍처에서 attention 개념을 도입하는데 도움을 주고, 많은 데이터의 중요성을 일깨워줬습니다.
그래서 발전한게 아래와 같이 Context 벡터도 여러개가 된 Attention을 포함한 Encoder-Decoder 아키텍처입니다.
Attention을 포함한 Encoder-Decoder 아키텍처
그러면 실제로 attention이 포함된 context가 어떤 값을 가지는지를 알면 이해가 더 잘될것입니다.
아래와 같습니다.
attention의 예시
예시는 나는 학생이다 => I am a _____ 로 바꾸는 것인데요.
빈칸을 유추하기 위해서 context vector인 c(4)가 필요하게 됩니다. 그리고 c(4)의 값은 각각의 단어와 attention을 얼마나 가지고 있는지를 포함하고있습니다.
나는
학생
이다.
c(4)의 attention 값
0.07
0.9
0.03
그래서 context값인 c(4)는 학생과 관련된 값일 확률이 높고(0.9) "나"라는 정보와도 0.07 정도의 관계가 있구나 이런 뜻을 함축하고 있음을 이해할 수 있었습니다.
그래서 문장의 모든 단어에 대해서 각 단어가 attention context 값을 가지게 되는것이 기본적인 개념입니다.
위치에 따라서 Context vector가 하나씩 존재하는 모습 (C1, C2, C3 ... Cm)
다음은 Query, key, value (QKV)의 개념을 이해해야합니다.
Query, Key, Value (QKV)
이 개념은 AI에서 처음 나온것은 아니고 정보를 찾기 위한 검색 엔진에서 처음 나온 개념입니다. (Information Retrieval)
Query를 주어서 가장 연관된 Key를 찾고 그 Key를 기반으로 Value를 찾아내는게 핵심 개념이죠
QKV의 예시
네이버와 같은 검색 엔진에서 사람들이 특정 단어(예시는 Seoul National University) 를 검색하면 그것과 가장 유사한 결과가 나와야하는게 바로 QKV의 개념과 동일 한 것입니다.
이것을 설명한 이유는 바로 Attention에서도 이 QKV 개념이 똑같이 사용 될 수 있기 때문입니다.
Attention에서 사용하는 3가지 타입의 벡터가 QKV의 개념을 가지고 있습니다.
Query(Q) = Decoder의 hidden state
핵심 : 무엇에 주목해야 할지 알려주는 벡터
Key(K) = Encoder의 Attention weight를 위한 hidden state
핵심 : Query가 주목할 대상인지 판단하는 기준 벡터
Value(V) = Encoder의 context vector 계산을 위한 hidden state
핵심 : 실제로 최종 정보를 추출할 때 사용하는 벡터
이 벡터들을 통해서 Attention weight 및 context vector를 계산합니다.
실제로 아키텍처상에서 사용되는 구조는 아래와 같습니다.
Attention에서 QKV를 사용하는 방식
Attention의 여러가지 타입들
Attention의 type으로는
cross vs self
soft vs hard
global vs local
의 개념이 있습니다.
Cross attention과 Self Attention의 차이
요약하자면
Cross attention은 서로 다른 sequence 사이의 관계성을 이해하기 위함. (e.g. 영어와 독일어)
Self attention은 같은 문장내에서의 관계성을 이해하기 위함. (e.g. 아래의 예시 참조)
으로 요약할 수 있습니다.
cross attention과 self attention
cross attention의 예시는
The animal didn't cross ~ 문장을 Das Tier uber quer ~ 문장으로 바꾸는것인데
The 가 Tier와 큰 연관이 있음을 보여줍니다.
즉, Input과 Output이 서로 다른 문장이며 서로의 관계성을 측정하는거죠.
반면, self attention은 서로 같은 문장을 사용하고있습니다.
The animaldidn't cross the street because itwas too tired.
이 문장에서 animal과 뒤의 it이 연관이 크다는것을 저장하기 위함이죠.
Soft attention과 hard attention
soft와 hard의 구분은 쉽습니다.
soft는 확률론에 근거하고 hard는 값이 정해져있는것이라고 생각하면 됩니다.
AI에서는 대부분 soft attention을 사용합니다. 왜냐하면 학습 가능한 (미분 가능한) 값은 바로 Soft attention이니까요.
그리고 global attention과 local attention은 전체 문장을 모두 attention 할것인지 아니면 일부만 할지에 대한 내용이라서 한줄로 설명을 하도록 하겠습니다.