

Few-Shot Learning 이해하기
회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면서 나온 내용의 일부입니다.가장 처음으로 학습한 내용이 바로 Few-Shot Lea
ray5273.tistory.com
Zero-shot learning, Metric Learning Approach 이해하기
https://ray5273.tistory.com/entry/Few-Shot-Learning-이해하기 Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면
ray5273.tistory.com
Meta Learning - MAML, Reptile 이해하기
이전 Few-Shot Learning과 Zero-shot Learning에 이어서 세번째로 글을 작성 해 봅니다.이전 글은 아래 링크를 통해서 확인할 수 있습니다. Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을
ray5273.tistory.com
Continual Learning, Knowledge Distilation 이해하기
이전 글에 이어서 작성합니다. Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면서 나온 내용의 일
ray5273.tistory.com
Multimodal AI에 대한 여러 의견과 주요 모델들
이전 문서들에 이어서 교수님의 강의를 기반으로 한 내용을 추가합니다. Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Mod
ray5273.tistory.com
위 글에 이어서 작성합니다.
우리 목적에 맞는 LLM을 싸고 빠르게 만들고 싶다는 요구사항이 많습니다.
그런 목적을 해결하기 위해서 Effective LLM 관련 기법과 MoE라는 기법을 소개하려고합니다.
1. Efficient Pretraining
먼저 Pretraining을 효율적으로 해보려고합니다.
다만, GPU 인프라나 AI 인프라가 잘 되어 있지 않은 우리나라에서는 많이 하려고 하지 않는 부분이기도 합니다. (미국 말고는 자체 모델은 거의 없는것 같긴하지만요)
Mixed Precision Training
학습 과정에서 Mixed Precision Training을 테크닉을 쓰면 효율이 좋아진다고 합니다.
요즘에는 일반적으로 많이 쓰는 floating point를 이용한 parameter 압축 방법이 있습니다.
그것이 FP32 -> FP16 처럼 floating point 자리를 옮겨주는 기법인데요.
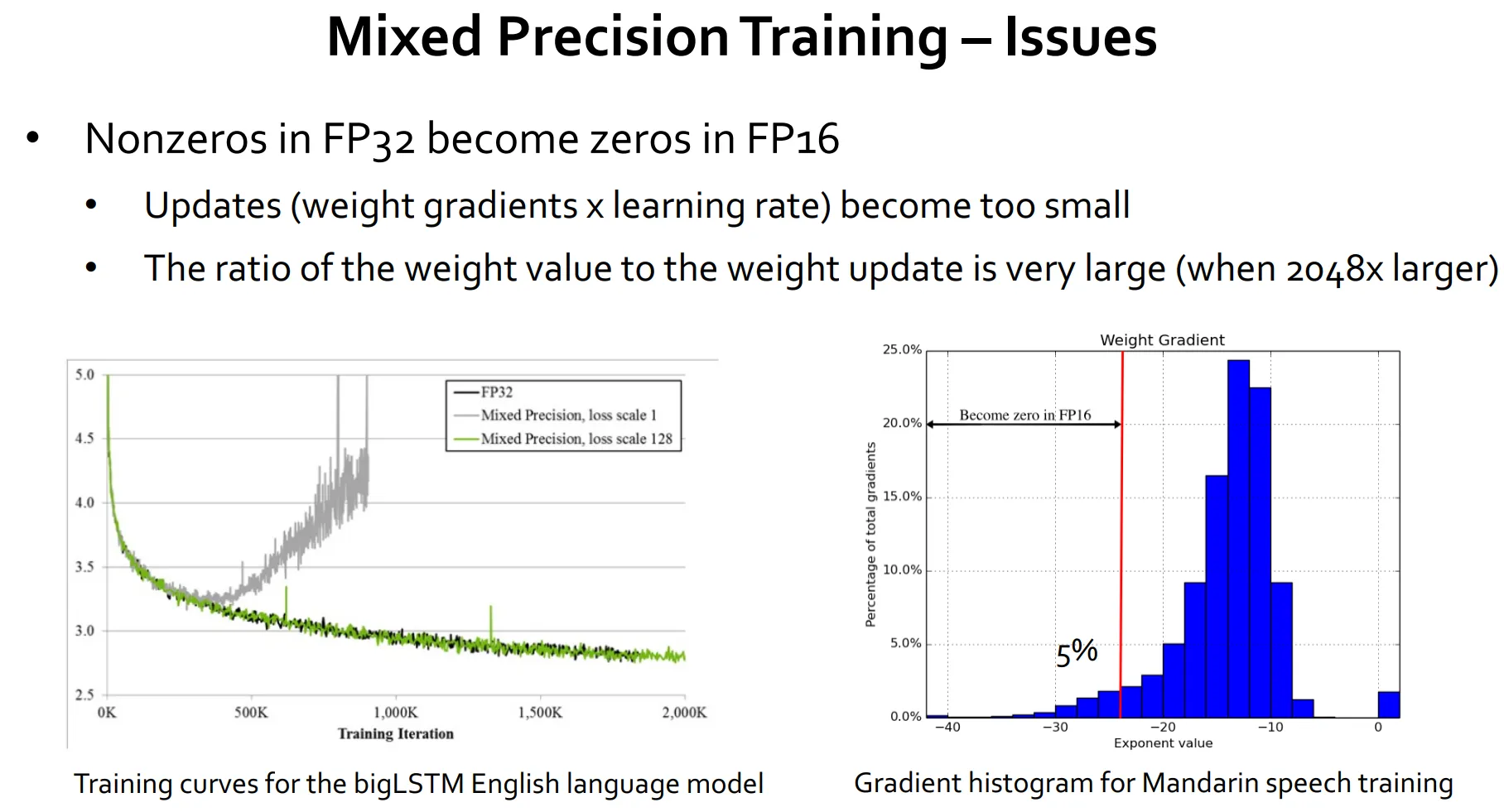
위의 실험 결과를 보면 FP32 → FP16 그냥 쓰면 회색 선과 같이 학습이 제대로 안되는 문제가 있습니다.
왜냐하면 학습할 숫자가 너무 작은 숫자라서 FP32에서는 표현이 잘 되는데 FP16에서는 0으로 표현되버려서 학습이 잘 안되는 케이스가 있기 때문이죠.
이 경우에 Mixed Precision Training을 처리해주면 초록색 선과 같이 기존과 동일하게 학습 할 수 있음을 보여줍니다.
이것의 키 아이디어는 Loss Scaling입니다.
Loss Scaling

위의 표를 보면 대부분의 FP32 범위는 x축의 -10 오른쪽 흰색 부분과 같이 잘 쓰지 않는 영역입니다.
대부분의 gradient 값이 엄청 작은 수에 몰려 있기 때문이죠
그런 이유로 FP16이 표현할 수 없는 빨간색 왼쪽 범위는 FP16으로 바로 변환하면 다 사라져 버려 학습이 손실 됩니다.
그러면 일정 값을 곱해서 gradient 값들을 다 오른쪽으로 옮기면 하면 값을 어느정도 살릴 수 있을거라는 생각이 들죠.
테스트를 해보니까 가장 왼쪽에 일부를 제외하고만 살려도 FP32랑 거의 성능이 똑같이 나온다고 합니다.
이것이 바로 Loss Scaling 입니다.
실제로 이를 구현하는 방식은 아래와 같습니다.
1. Forward pass의 loss의 value만 특정 값을 곱해서 scale을 해주면 gradient값이 동일하게 곱해지는 효과가 있습니다.
2. 그리고 나서 backward pass 를 하고 나서 다시 descale을 하게 되면 원래 얻고싶었던 값과 동일한 값을 얻을 수 있습니다.
그러면 드는 생각은 Scale Factor는 어떤식으로 값을 정하는가에 대한 궁금증이 생기죠
Scale Factor 값을 어떻게 정하는지
결론부터 말하자면 충분히 큰 S를 해보고 overflow가 나면 S를 줄이는 방식을 사용한다고 합니다.
한번정도 overflow 났다고 해서 학습이 아예 망가지고 그러진 않아서 이런 방식을 택해도 괜찮다고 하네요.

아래 결과를 보면 모델마다 Mixed Precision Training의 효과는 조금씩 다 다르다는것을 확인할 수 있습니다.
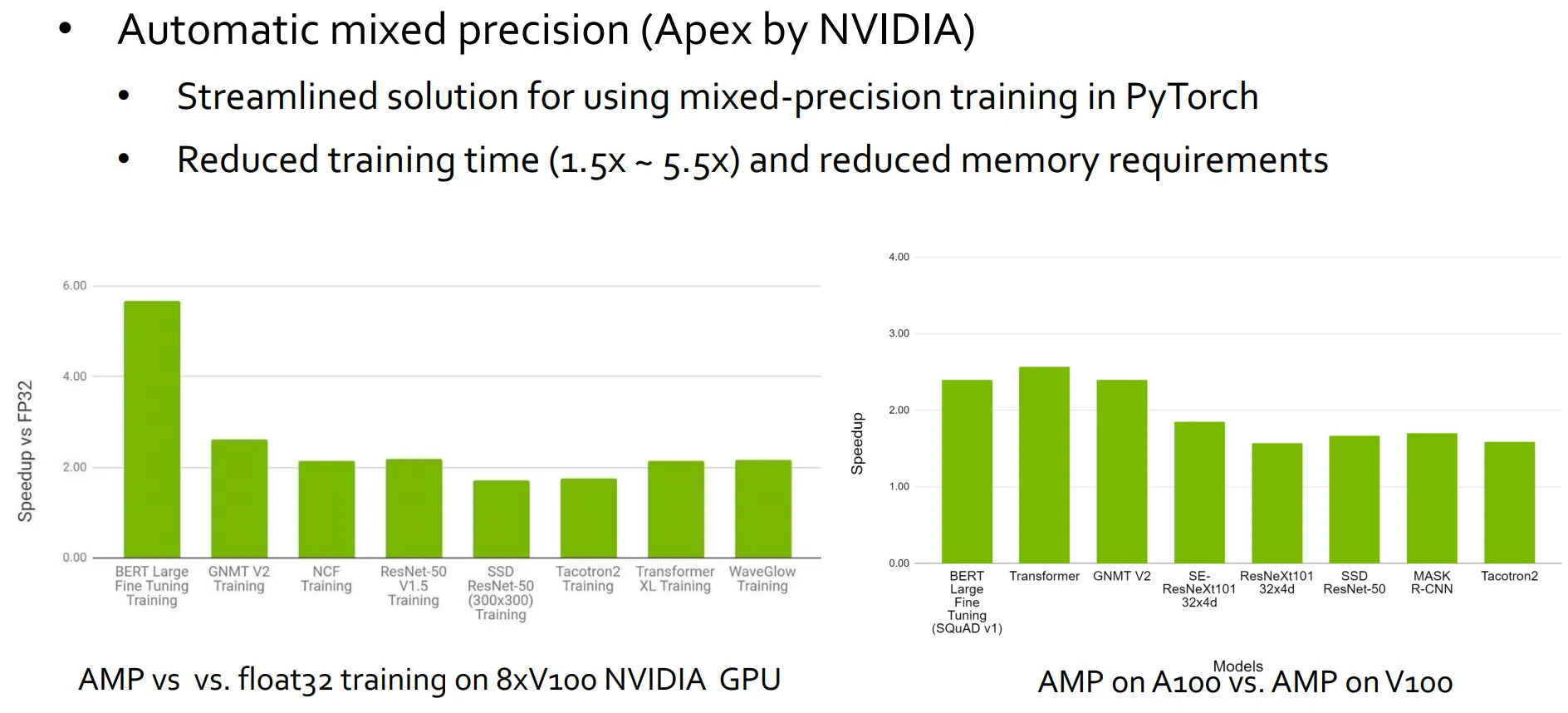
일반적으로는 학습 속도가 1.5 ~ 5.5배 빨라진다고 알려져있습니다.
또한, 대중적으로 많이 쓰는 최적화 방식이라서 Pytorch 같은 AI 패키지에는 이미 기본적으로 포함되어있습니다.
2. Efficient Fine-Tuning
두 번째는 Fine-Tuning을 효율적으로 하는 방법입니다.
가장 먼저 소개드릴 내용은 가장 대중적으로 많이 쓰는 LoRA입니다.
LoRA(Low Rank Adaption)
대부분의 모델에서 LoRA는 일반적으로 포함되어 있다고 합니다.

왜 LoRA를 사용하는가?
여러가지 이유가 있습니다.
- LLM 모델 크기의 폭발적 증가 중입니다.
- 수십억, 수천억 개 이상의 파라미터를 가진 모델이 범용적으로 쓰이면서, 이 모든 파라미터를 미세조정하는 것은 자원 낭비가 크고 현실적으로 어려운 경우가 많습니다.
- 또한, LoRA를 통해 학습 효율 상승을 노릴 수 있습니다.
- 모델 전체 파라미터를 학습할 필요 없이, rank가 낮은(=가중치 행렬 차원이 매우 작은) 부분만 학습하면 되므로 학습 속도가 빨라지고 메모리 사용량이 줄어듭니다.
- 응용 시나리오가 다양합니다.
- Task 별로 parameter를 보유할 수 있으니 Task 별로 다양하게 parameter를 추가할 수 있습니다.
- 예를 들어, 여러 가지 도메인(의학, 법률, 챗봇 등)으로 모델을 확장하고 싶다면, 원본 모델을 통째로 복제해서 미세조정하기보다는 LoRA 같은 방법을 통해 훨씬 가벼운 추가 파라미터(LoRA weight)만 관리하면 됩니다.

위의 그림으로 보자면
1. W_0은 기존의 LLM 모델의 큰 weight
2. A와 B는 내가 추가로 학습시키고 싶은 적은 양의 데이터 학습하면 업데이트 되는 행렬 (parameter)
라고 볼 수 있습니다.
A x B의 사이즈가 W와 동일한데 (A x B) 자체를 하나 더 보유하기에는 용량이 너무 큽니다.
그래서 A, B 행렬 하나씩 보유해서 학습한 후 실제로 쓸때는 A x B 값을 구해서 기존 Weight에 더하자는게 아이디어입니다.
그래서 Low-Rank 라고 표현하는 것이죠.
디테일하게는 A,B를 아래와 같이 initialize 한다고 하네요.
- A - Gaussian Initialization을 함
- B - 그냥 0으로 initialize 함.
QLoRA
이름으로 부터 유추할 수 있듯 LoRA에 quantization을 추가한 것입니다.
메모리 사용을 상당히 줄였다고합니다.

성능도 훌륭하게 유지하면서 말이죠
QLoRA는 기본적으로 k-bit quantization을 사용하여 용량을 줄일 수 있습니다.
이를 먼저 간략하게 설명하려고 합니다.
k-bit quantization

위으 그림과 같이 이해해보자면 FP32 기반으로 학습된 param의 양쪽 끝단의 값중에 절대값이 큰 값을 선택해서
이를 INT8의 최대값인 127에 할당하는 것입니다.
예시에서는 10.8을 127로 대응을 시켰습니다.
그리고 다른 모든 param 값에 같은 값을 곱해서 [-127, 127] 범위에 할당시키는 것이죠 (소수점은 모두 반올림합니다.)
그러면 FP32 -> INT8로 용량을 줄일 수 있게 됩니다. (1/4 용량, 75% 향상)
다만, 단점으로는 만약 양 끝단의 outlier값이 너무 커버리면 실제 많은 param 값들이 특정 구간에 몰려버리는 문제가 있을 수 있습니다.
그래서 QLoRA는 무엇인가
LoRA + 아래 3가지 테크닉을 활용해서 만들어졌다고 합니다.
아래 내용들을 통해서 용량을 많이 줄였다는것을 강조합니다.
- 4-bit NormalFloat quantization
- Double quantization
- block-wise quantize를 하고
- quantized 된 256개의 constant를 가져와서 다시 quantize를 한 것 이라고합니다.
- 256 *8-bits + 1 * 32-bit quantization constants
- Paged Optimization
- 이건 그냥 Nvidia의 memory feature를 사용한 것이었습니다.
Adapter-based tuning
Adapter based tuning의 경우에는 번역 모델에서 많이 사용합니다.
왜냐하면 모든 언어에 대해서 모델을 따로 두면 너무 비효율적이라고 느껴지죠
그래서 adapter-based tuining을 도입해서 => 각 언어에 대해서 adapter를 두는 방식 (작은 모델) 으로 해결합니다.
큰 모델에 adapter라는 작은 모델을 붙이는 식입니다.

Adapter의 경우 Transformer 블록 내에 왼쪽 그림과 같이 별도의 작은 모듈 (Adapter Layer)를 추가하고 이 모듈만 학습하는 것입니다.
Adapter layer의 내부는 오른쪽과 같습니다.
3. Efficient Inference
Speculative Decoding
Decoding의 의미는 이전 단어를 기반으로 계속 새로운 단어를 만들어 내는것을 Decoding이라고 합니다.
Speculative Decoding (추론 디코딩)을 쓰면 엄청 빨라진다고 합니다.
아이디어
아이디어는 아래와 같습니다.
Decoder를 아래와 같이 두 개를 가지고 있습니다.
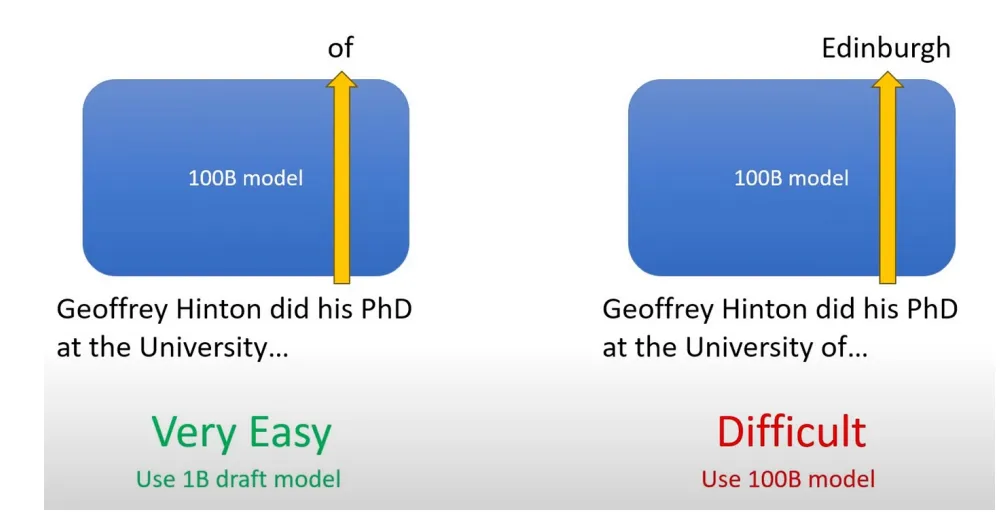
1. 작은 LLM 모델 (Guide Model) - e.g. 1B
- 작고 빠른 모델이 미리 여러개의 후보 토큰 시퀀스를 만들어 냅니다.
- 이 모델이 출력하는 시퀀스가 높은 확률로 정확할 것이라고 가정합니다.
2. 용량이 큰 main LLM 모델 (Target Model) - e.g. 100B
- 크고 느린 모델이 Guide Model의 예측을 검증하고 보정합니다.
- 그래서 Guide Model의 예측이 맞으면 그대로 사용하고, 틀리면 큰 모델이 그 부분만 다시 보정합니다.
결과적으로 추론 속도가 훨씬 빨라집니다.

위의 예시에서는
1. 초록색을 작은 LLM(Guide Model)이 생성한 것이고
2. 빨간색은 Guide Model이 생성했다가 틀려서 큰 모델 (Target Model)이 고쳐 준 부분이죠.
3. 그러면 고쳐진 부분 이후부터는 다시 작은 LLM이 다시 생성을 시도해서 문장 완성을 시작합니다.
4. 이를 반복하는 방식으로 동작합니다.
사용처
- 실시간 응답이 중요한 서비스
- 비용 효율성을 높이면서 LLM을 서비스에 적용 할 때
- 대형 LLM의 추론 시간이 너무 길어지는 경우
등에 Speculative Decoding을 활용해서 성능을 올릴 수 있습니다.
MoE (Mixed of Experts)
MoE는 모든 질문에 대해서 매번 엄청나게 큰 모델을 써서 높은 비용으로 처리할 필요가 없지 않나 라는 질문에서 시작된 것 입니다.
1. 기본 개념
MoE는 다수의 전문가 네트워크(Experts) + Gating Network로 구성 되어있습니다.
- Experts : 서로 다른 작은 네트워크 (Feed Forward Layer)들이 다수 존재합니다.
- Gating Network : 입력을 보고 어떤 전문가(Expert)를 활성화할지 선택합니다.
- 일반적으로는 소수 (2~3개) 만 활성화 된다고 하며 나머지는 사용되지 않는다고합니다.
- 이를 통해 연산량을 줄이고 Sparse 연산을 가능하게합니다.
2. MoE의 작동 방식

1. 입력처리
- 입력이 들어오면 Gating Network가 입력을 기반으로 가장 적합한 Expert를 선택합니다.
- Softmax 혹은 Top-K를 활용해서 전문가 선택 확률을 구해서 활성화합니다.
2. 선택된 전문가 활성화
- 선택된 소수의 전문가만 활성화되어 연산을 수행합니다.
- e.g. 16개의 expert 중에 2개만 활성화 되면 연산량이 1/8이 되는 것입니다.
3. 출력 결합
- 활성화된 전문가들의 결과를 가중합의 형태로 결합해 최종 출력을 생성합니다.
3. MoE 모델을 학습할때의 어려움
학습시 imbalance 하다는 문제가 있습니다.
- 처음에 몇개의 network를 선택하고 학습하면 처음에 선정된 expert network를 계속 선택하는 경향이 커집니다.
- 학습되기 시작한 network에서 더 대답을 잘 할 확률이 높기 때문이죠.
그래서 이런 문제가 발생하는 것을 최대한 막아야 하는데 이는 아래와 같은 방법으로 해결한다고 합니다.
세부 내용에 대해서는 아직 제대로 이해하고 정리하지 않아서 키워드만 적어두도록 하겠습니다.
1. Load balancing Loss 도입
- Gating Network에 Load balancing loss를 추가해 expert 선택을 균등하게 유지하는 방식
2. Noisy Gating
- Gating Network에 작은 노이즈를 추가해 expert 선택 확률 분포를 더 고르게 하는 방식
3. Expert Capacity 제한
- 각 전문가가 처리할 수 있는 최대 입력의 수를 제한하는 방식
MoE에 대한 조금 더 자세한 설명은 아래 사이트에서 확인할 수 있습니다.
Mixture of Experts Explained
huggingface.co
'CS 지식 > AI 관련' 카테고리의 다른 글
| Transformer 바닥부터 이해하기 - 1. Attention 이해하기 (0) | 2025.03.08 |
|---|---|
| Word Embedding에 관련된 질문 그리고 해답 찾기 (0) | 2025.03.05 |
| Transformer 바닥부터 이해하기 - 0. Transformer 이전의 NLP 역사들 (0) | 2025.02.12 |
| Multimodal AI에 대한 여러 의견과 주요 모델들 (2) | 2025.02.09 |
| Continual Learning, Knowledge Distilation 이해하기 (0) | 2025.02.02 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



