


이전 문서들에 이어서 교수님의 강의를 기반으로 한 내용을 추가합니다.
Few-Shot Learning 이해하기
회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면서 나온 내용의 일부입니다.가장 처음으로 학습한 내용이 바로 Few-Shot Lea
ray5273.tistory.com
Zero-shot learning, Metric Learning Approach 이해하기
https://ray5273.tistory.com/entry/Few-Shot-Learning-이해하기 Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면
ray5273.tistory.com
Meta Learning - MAML, Reptile 이해하기
이전 Few-Shot Learning과 Zero-shot Learning에 이어서 세번째로 글을 작성 해 봅니다.이전 글은 아래 링크를 통해서 확인할 수 있습니다. Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을
ray5273.tistory.com
Continual Learning, Knowledge Distilation 이해하기
이전 글에 이어서 작성합니다. Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면서 나온 내용의 일
ray5273.tistory.com
In-Context Learning
- GPT3는 특정 목적을 위한 AI가 아니라 다목적 (General)하게 동작하기 위함입니다.
- Context 안에서 사용자의 의도를 이해해서 잘 하려고 하는게 목표입니다.
- AI가 Inference할때 스스로 사용자의 의도를 캐치하고 대답을 한다고 합니다.
- 그래서 사실 Few-shot learning이 실제로는 training이 아니지만 위와 같은 의도에 따라서 few-shot learning으로 표현하는 것입니다.

Chain-Of-Thoughts (COT) Prompting
COT는 질문에 대한 답만 하는게 아니라 답을 도출하기 위한 풀이 과정을 적어줌으로써 성능을 10~20% 올렸다고 합니다.
이게 중요한 이유는 모델 사이즈를 별도로 늘리지 않고 프롬프트만으로 해결해서 의미있게 사용되는 개념입니다.

위의 내용이 아주 중요한 장점이고 반대로 단점은 하나의 문제를 풀려고 K개의 풀이 과정을 만드는게 너무 번거롭고 귀찮은 일입니다.
Zero-Shot COT
간단하게 프롬프트로 "차근 차근히 생각해봐" 라는 내용을 입력하니까 성능이 확 올랐다는 것입니다.
=> 이런 이유로 프롬프트 엔지니어라는 직종이 떠오른것입니다.
질문 후 풀이 과정을 유도한다는 의미에서 COT라고 불리며
풀이 과정을 추가하지 않고, "차근 차근히 생각해봐"를 대신 넣어서 zero-shot이라고 표현합니다.
GPT-4부터 아래 두 가지 특징을 강조하기 시작했다고합니다.
- multi-modal
- 사람이 보는 시험을 얼마나 잘 해결하느냐를 강조함.
또한, OCR은 딱히 학습시키지 않았는데도 잘 처리해주는 특징을 가지고 있다고 합니다.
교수님의 의견
- OpenAI가 GPT 주제를 하나씩 낼 때마다 연구 흐름까지 바꾸고 있다고 합니다.
- 사람마다 정의가 다르지만 교수님 의견으로는 Language Model은 거의 AGI에 도달했다는 의견을 내셨습니다.
- 사람의 Intelligence를 넘은 경우 AGI라고 판단하신다고하네요
- 또한, AGI가 달성하면 AI는 더 이상 사람을 흉내 내지 않는 특징이 있다고 합니다.
- GPT-4o 정도의 Multi-modal AI는 학계에서는 구현 조차 못하고 있다고 하네요.또한, LLAMA 3.0 ~ 3.2 까지의 개선은 그렇게 크지 않다고 생각하고노래를 부르면서 대화하는 Multi-Modal LLM은 OpenAI에서 만든 모델 말고는 없다고하고 있기는 하더라도 성능의 차이가 엄청 심하다고 하네요.
- 또한 GPT 4o의 Response time이 232ms정도며
- 한숨같은 패턴이나 감정을 통해서 다르게 얘기하는것까지 가능하다고 합니다.
- Open-Source와 Closed-Source의 갭이 상당히 벌어져있다고 하네요.
- 그래서 교수님 의견으로는 Open-Source로 Closed-Source를 이기는게 말이 안된다고 생각하신다고 하네요.
Multi-Modal LLM (MLLM)을 어떻게 만들것인가?
Multi-Modal LLM의 핵심은 Connection Module을 어떻게 만드느냐가 중요하다고 합니다.
나머지의 Language Model, Vision Encoder는 기존에 존재하는 모델들을 가져다 쓴다고 합니다.

CLIP (Zero-shot Classifier)
예전에는 모델 + fine-grained training을 추가해서 매번 학습시키는 방식으로 모델을 개선했습니다.
CLIP은 위와 같이 하지 않고 학습을 하지 않고 바로 모델에 적용시키는 방법이라고 합니다.
(plugin 식으로 쓰겠다)
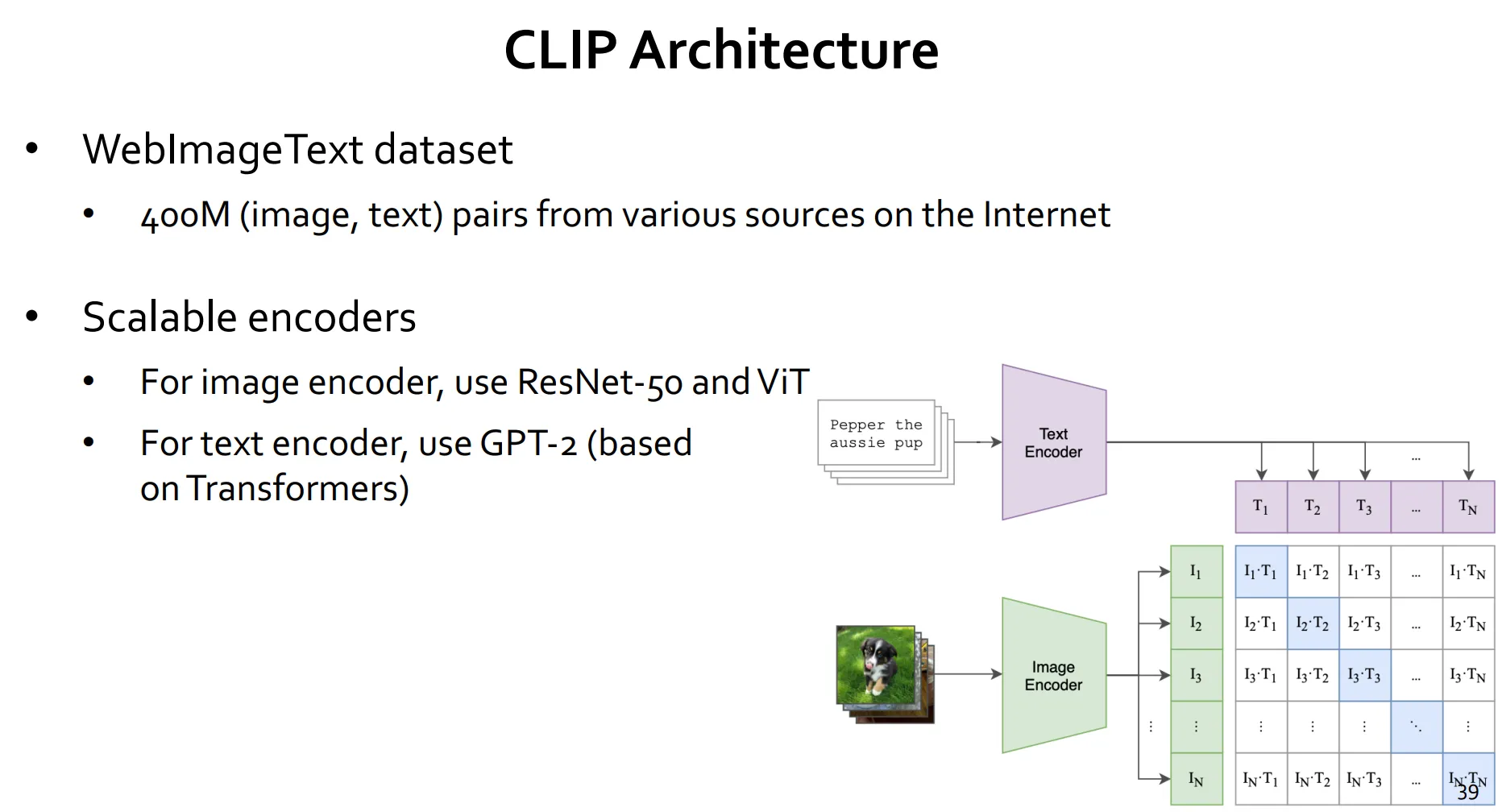


Zero-shot clip으로 인터넷에 많은 사진들을 테스트해봤을때는 성능이 잘 나옵니다.
반대로 당연하게도 데이터 셋이 많이 없는 경우에는 문제를 잘 해결하지 못합니다.
- MNIST의 경우에도 현재는 인터넷에 존재하지 않는 데이터셋이라서 성능이 낮았습니다.
아래의 구조와 같이 CLIP은 프롬프트가 상당히 중요한 역할을 한다고 합니다.
아래 그림에서 "A Photo of a {object}" 가 프롬프트로 사용되는 것이죠.

CLIP의 한계
1. 데이터 편향성 및 불균형 - 인터넷에서 수집한 대규모 이미지-텍스트 페어로 학습되어 편향이 있을 수 있습니다.
2. 프롬프트 민감성 - 프롬프트의 표현 방식이나 단어 선택에 따라 모델 출력이 달라집니다.
3. 적대적 공격에 대한 취약성 (Adversarial Vulnerability) - 약간의 이미지 변형이나 노이즈에도 모델이 쉽게 오인식 가능하다고 합니다.
DeepMind Flamingo 모델
Flamingo는 GPT-3를 Multi-modal로 바꾼것이라고 합니다.
Flamingo는 이미지와 텍스트라는 두 가지 서로 다른 데이터 형태를 동시에 다룹니다.

아키텍처는 아래와 같은 특징을 보입니다.
- 언어 모델과 비전 인코더의 결합
- 트랜스 포머 기반의 언어모델 + 비전 인코더 (CNN ,Vision Transformer)를 결합해서 사용합니다.
- Gated Cross-Attention 매커니즘
- 이미지에서 추출한 특징을 언어모델에 통합하기 위함입니다.
- 언어 모델이 언제, 어느정도로 이미지 정보를 참조해야하는지를 조절해서 텍스트와 이미지 사이의 효과적인 상호작용을 가능하게 합니다.

위의 그림에서 언급된 Perceiver라는게 있습니다.
실제로 Flamingo는 Perceiver에서 사용하는 cross-attention 개념과 유사하게 작동하는 resampler를 사용하고있습니다.
아직 Perceiver를 정확하게 이해를 하지는 못했지만 동작 방식은
압축 하려는 Sequence의 vector를 cross-attention, self-attention을 반복하여 일종의 압축된 sequence를 만들 수 있다고 합니다.

Perceiver에 대해서는 조금 더 이해를 한 후 내용을 추가해보도록 하겠습니다.
Transformer의 등장의 이유는?
NLP의 가장 큰 문제는 모호성이라고합니다.
예를 들면 bank 라는 단어만 보면 정확하게 어떤 뜻을 의미하는지 알수가 없습니다. (언어가 기본적으로 모호성을 가지고 있기도 하죠)
그래서 해당 단어에 대해 wordToVec을 하면 무조건 하나의 Vector가 나와서 강둑/은행 둘 중에 하나로 반드시 정해져야하는 문제가 있었습니다.
또한, 숙어도 다른 뜻으로 해석되어야하는 케이스가 많은데, 직독 직해식으로 고정적인 해석이 나와서 문제였습니다.그래서 Context를 고려해서 단어를 만들겠다는게 Transformer입니다.
Flamingo의 Transformer Architecture
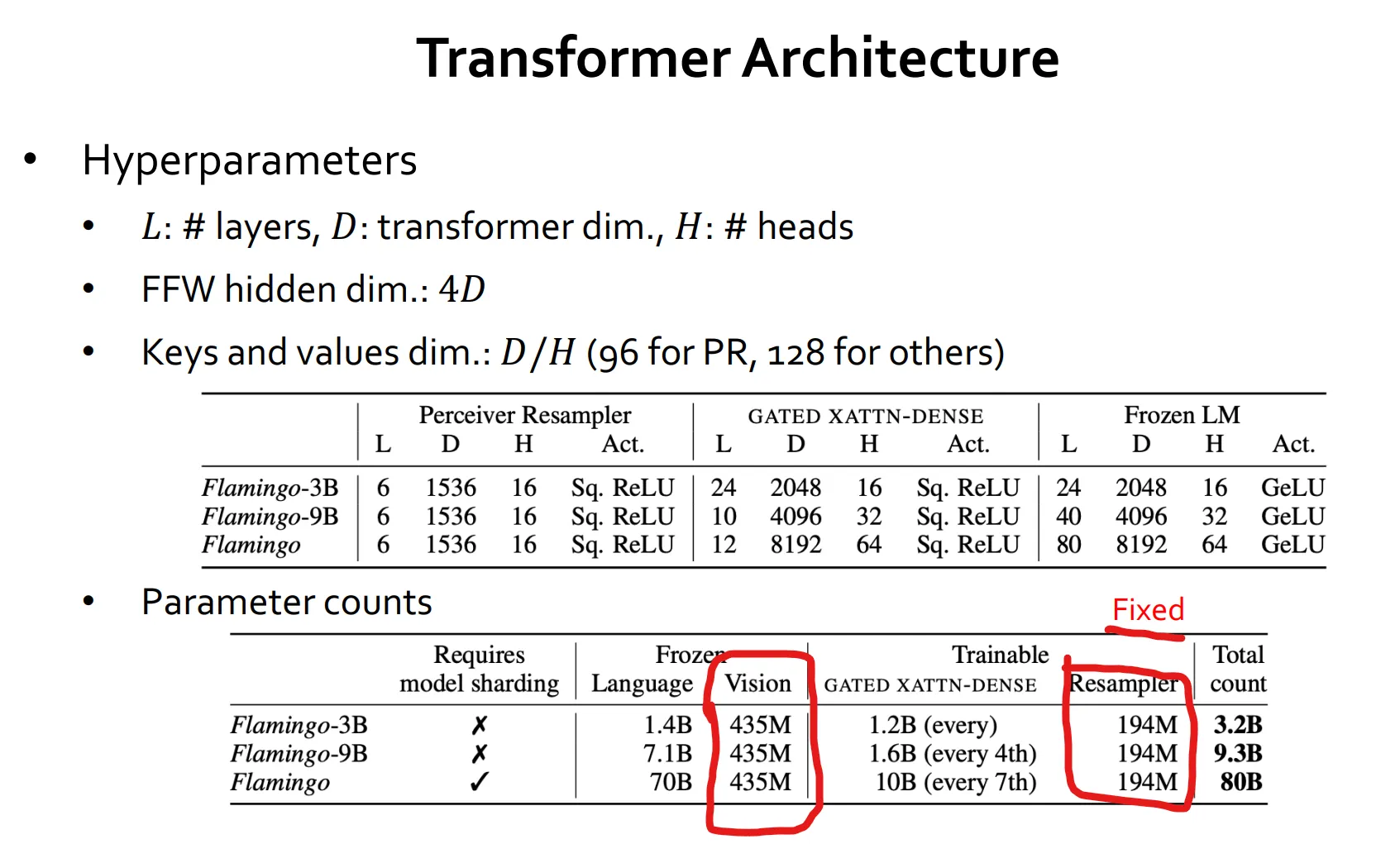
perceiver 값은 모델의 크기가 커질때마다 더 커진다고합니다. -> 1.2B , 1.6B, 10B
- 레이어가 작을때는 모든 Layer 마다 끼워넣을 수 있었습니다.
- 그러나 모델이 커지면 매 4 Layer마다 끼워넣거나, 매 7 Layer마다 끼워넣는식으로 줄인다고합니다.
막상 Flamingo 70B 모델이여도 Vision 데이터는 435M 밖에 없다고 합니다.
즉, 사실상 LLM 모델이라는 거죠
그래서 비전 데이터가 많지 않아 문제가 많다고 합니다.
또한, 비전은 모델의 크기를 키워봐야 성능이 안올라서 문제가 많다는 의견을 주셨습니다.
따라서 Language는 AGI 영역이라고 보는데 Vision은 AGI까지 한참 멀었다는 결론을 내렸다고하네요.
'CS 지식 > AI 관련' 카테고리의 다른 글
| Effective LLMs and MoE (Mixture of Experts) (0) | 2025.02.12 |
|---|---|
| Transformer 이전의 NLP 역사들 (0) | 2025.02.12 |
| Continual Learning, Knowledge Distilation 이해하기 (0) | 2025.02.02 |
| Meta Learning - MAML, Reptile 이해하기 (0) | 2025.01.30 |
| Zero-shot learning, Metric Learning Approach 이해하기 (0) | 2025.01.28 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



