


이전 Few-Shot Learning과 Zero-shot Learning에 이어서 세번째로 글을 작성 해 봅니다.
이전 글은 아래 링크를 통해서 확인할 수 있습니다.
Few-Shot Learning 이해하기
회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면서 나온 내용의 일부입니다.가장 처음으로 학습한 내용이 바로 Few-Shot Lea
ray5273.tistory.com
Zero-shot learning, Metric Learning Approach 이해하기
https://ray5273.tistory.com/entry/Few-Shot-Learning-이해하기 Few-Shot Learning 이해하기회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면
ray5273.tistory.com
Meta Learning
Meta Learning의 개념
사람도 어떤 공부에 있어서 빨리 배우는 사람과 늦게 배우는 사람이 나뉘는것을 경험적으로 알 수 있죠.
같은 내용으로 학습을 하더라도 몇몇은 이해를 잘 한 사람이 있고 아닌사람이 있게 되는 것이죠.
그래서 사람에게 지능이 높다는 의미는 적은 양으로 어떤 내용을 빨리 배우고 이해 한다는 것을 의미합니다.
AI도 그런식으로 적은 내용의 학습으로도 좋은 AI 모델로의 학습을 할 수 있지 않을까 이런 개념에서 도입된것이 Meta Learning이라고 합니다.

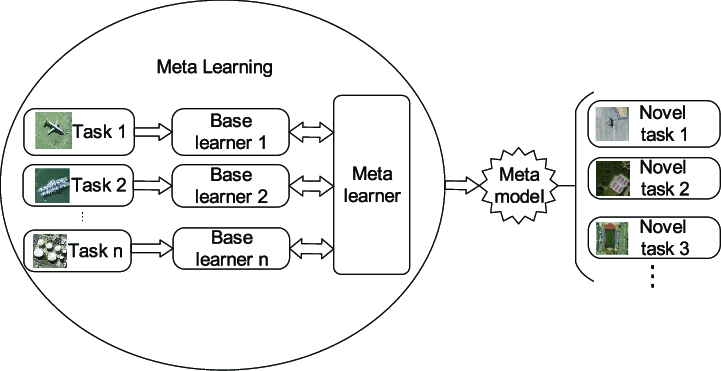
요약을 하자면 그림과 같이 Meta Learner가 최종 예측을 하는 가장 최상위 Learner입니다.
그리고 여러개의 Learner (그림에서는 Base Learners)가 존재하고, 개별 Learner마다 Task가 존재합니다.
각 Task 마다 Training Set이 있어서 그것을 통해서 Base Learner를 학습합니다.
Meta Learning에 대한 교수님의 짤막한 의견
예전에는 Few-Shot learning과 별개의 개념으로 쓰였지만 요즘은 거의 동일하게 쓴다고합니다.
평가 (Evaluation) 자체를 Few-Shot learning으로 많이 하기 때문이라네요.
MAML: Model-Agnostic Meta-Learning
MAML은 새로운 Task에 빠르게 적용하기 위한 최적의 parameter initialization을 찾는 것입니다.
- 이를 통해서 적은양의 데이터로도 빠르게 Task를 최적화 하기 위함입니다.
MAML에 대한 교수님의 부연 설명
범용성이 좋다.
- 모델을 모르고 적용할 수 있는 방식이라고 합니다.
- 즉, 어떤 모델 구조에도 적용할 수 있다고합니다.
e.g. CNN,RNN, 트랜스포머, 강화학습, Image classification 등.
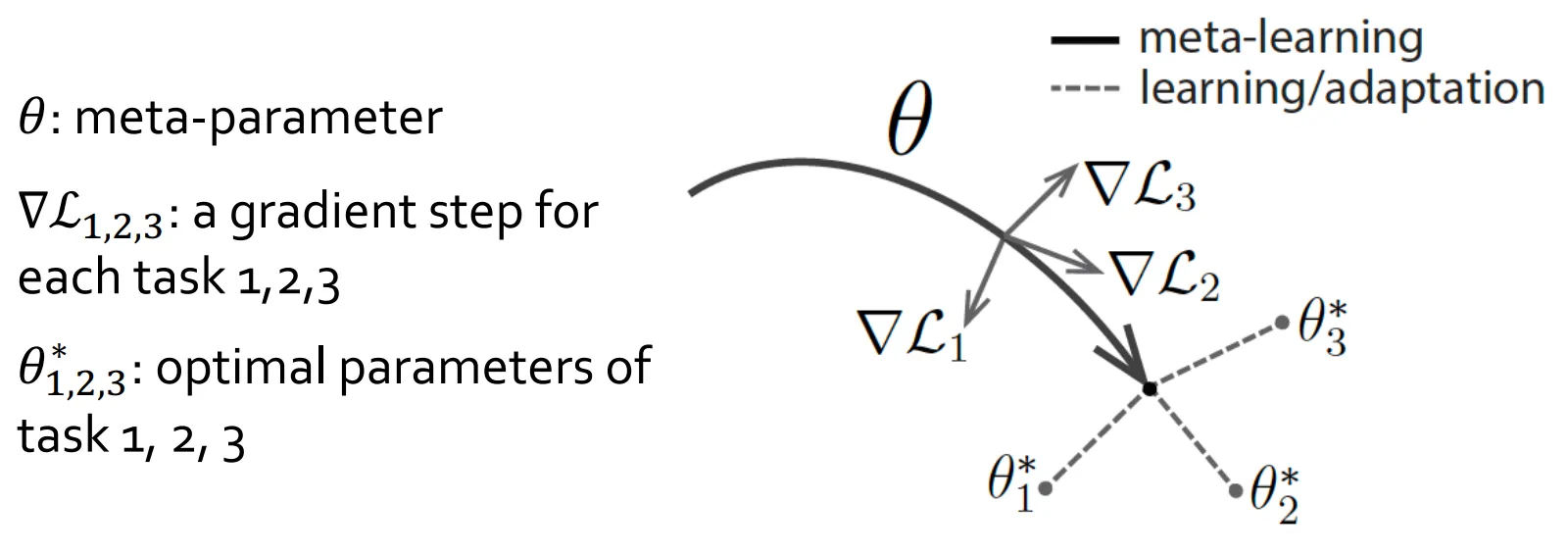
최적의 Initialization이란 무엇인가에 대해서 고민해 보면 아래와 같은 항목들을 만족하면 됩니다.
1. 적은 수의 gradient step만 밟고도 optimization이 되면 좋은 initialization이 되는 것 입니다.
2. Training의 개수가 적으면 적을수록 좋습니다.
3. Overfitting은 막을 수 있어야합니다.
MAML 알고리즘
MAML 학습 알고리즘은 설명이 잘 되어있는 곳이 아주 많기도 하고
자세하고 정확한 설명은 쉽지않은데 대략적으로만 해보겠습니다.
대략적으로 요약하자면 1. Inner Loop 학습과 2. Outer Loop 학습으로 나뉩니다.

1. Inner Loop : 태스크 별 학습
- 태스크 샘플링 - 다양한 태스크 Ti 들로 부터 하나를 골라 Support Set (학습용 소량 데이터) 와 Query Set (평가용 데이터) 로 분할합니다.
- Support Set으로 빠른 adaption
- 현재 메타 파라미터 θ(theta)를 초기값으로 사용합니다.
- θ에서 시작해서 Support Set에 대해 몇번의 Gradient Update (보통 1~5회)를 수행합니다.
- 그 결과 θ'i 라는 태스크 Ti에 특화된 임시 파라미터를 얻습니다.
- Query set에서 성능 확인
- θ'i 를 사용해 Query Set을 예측하고 손실 (Loss : LTi(θi′))를 측정합니다.
- 이때 계산된 손실 - LTi(θi′) 는 Ti 입장에서 메타파라미터 θ가 얼마나 좋은 초기값을 제공했는지 평가합니다.
2. Outer Loop : 메타 업데이트
- 다양한 태스크에 대한 손실 합산
- 여러개의 태스크 (T1,T2,..., Ti) 각각에 대한 위 1 (Inner loop) 과정을 수행하고
- θ'i 로 부터 얻어진 query loss 들의 합을 계산합니다.
- 메타 파라미터 θ 업데이트
- θ를 메타 손실 Sum {LTi(θi′)} 의 그래디언트를 이용해 업데이트합니다.
- θ←θ−β∇θ∑iLTi(θi′) (위의 pseudocode의 line 8)
- 여기서 이차 미분 과정이 들어가서 계산량이 많아지는 문제가 있기도 합니다.
- 반복
- 다른 태스크에도 같은 과정을 반복하면서 θ가 점차 다양한 태스크에도 빠르게 적응 가능한 초기값으로 학습됩니다.
MAML이 중요한 이유
MAML이 중요한 논문이자 방식이었던 이유는 Gradient-based optimization을 썼기 때문입니다.
- MAML 이전의 대부분의 initialize는 대부분 gradient-based optimization으로 하는 경우 랜덤으로 initialize를 합니다.
- SGD를 쓴다는 의미는 파라미터 값을 찾아내기 위해 업데이트가 기본적으로 엄청 많이 필요한 학습이라고 가정하는것입니다.
- 그런 이유에서 SGD + Few-Shot Learning은 좋은 궁합이 아닙니다. (잘 동작하지 않을 확률이 높다는 것이죠.)
- 즉, SGD는 AI 학습에 있어서 엄청나게 많이 쓰는 방법인데, Few-shot에 대해서 약점이 있었습니다.
- 그런 이유로 데이터가 적은 학습의 경우에는 베이지안 방식으로 해결 했었는데 해당 방식은 연산량이 너무 높아 좋은 방식은 아니었습니다.
- 그런데 그 문제를 해결하기 위해서 MAML이라는 좋은 방식을 제시 했기 때문에 이 논문이 중요하다고 평가받는다고 합니다.
Reptile
Reptile은 OpenAI에서 발표한 MAML의 이차 미분 계산을 피하고 Simple First-Order 방법을 사용한 Meta Learning 기법입니다.

저도 잘은 모르겠지만,,
θ의 복잡한 계산을 하지 않고 학습후에 달라진 θ 파라미터 차이만을 이용하겠다.
즉, 계산을 좀 단순화 했다 이정도로 받아들였습니다.
아래와 같은 과정을 반복한다고하네요.
1. 초기화
- 메타 파라미터 θ를 무작위 혹은 사전학습된 값으로 초기화.
2. 반복(Outer Loop)
- 태스크 Ti 샘플링
- 사전에 정의된 태스크 분포(예: 다양한 이미지 분류, 강화학습 환경 등)에서 하나를 임의로 선택.
- Inner Loop 학습
- θ를 복사해 를 만듦(초기값).
- 태스크 Ti의 데이터를 몇 번의 미니 배치 학습(SGD 등)으로 θ′를 업데이트.
- 그 결과 태스크 Ti에 특화된 θ′를 얻게 됨.
- 메타 업데이트
- θ를 θ′ 쪽으로 이동시키는 단순 1차 업데이트 적용
- θ←θ+ϵ(θ′−θ)
- 은 메타 학습률(outer loop 학습률).
3. 결과
- 위 과정을 여러 태스크에 대해 반복하면서, θ가 점차 “새로운 태스크에도 빠르게 적응할 수 있는 좋은 초기 파라미터”로 수렴하게 됩니다.
요약
| 항목 | MAML | Reptile |
| 핵심 아이디어 | 초기 파라미터 θ로 부터 Inner Loop를 거친 θ' 가 Query loss를 최소화 하도록 이차 미분까지 고려해 최적화 | 태스크 학습 후 파라미터 변화량 (θ' - θ)을 단순히 1차 업데이트로 반영 |
| 계산 복잡도 | 이차 미분 계산 필요 | 이차 미분 없음 |
| 학습 속도 | 정확도가 높고 메타 러닝 특성이 잘 드러남 |
MAML과 유사한 수준의 성능 보임 |
| 설계 구조 | Outer Loop, Inner Loop에서 손실 함수를 따로 계산, 그래디언트 역전파를 통해 메타 업데이트 | Inner Loop에서 나온 최종 파라미터와 θ의 단순 차이만으로 메타 업데이트 |
참고
https://www.ibm.com/kr-ko/think/topics/meta-learning
메타 학습이란 무엇인가요? | IBM
'학습을 위한 학습'이라고도 불리는 메타 학습은 인공 지능(AI) 모델이 새로운 작업을 스스로 이해하고 적응하도록 학습시키는 머신 러닝의 하위 범주입니다.
www.ibm.com
'CS 지식 > AI 관련' 카테고리의 다른 글
| Multimodal AI에 대한 여러 의견과 주요 모델들 (2) | 2025.02.09 |
|---|---|
| Continual Learning, Knowledge Distilation 이해하기 (0) | 2025.02.02 |
| Zero-shot learning, Metric Learning Approach 이해하기 (0) | 2025.01.28 |
| Few-Shot Learning 이해하기 (0) | 2025.01.28 |
| Advanced RAG Techniques - Query expansion, Cross-encoder and Dense Passage Retrieval(DPR) (2) | 2024.12.29 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



