


https://ray5273.tistory.com/entry/Few-Shot-Learning-이해하기
Few-Shot Learning 이해하기
회사에서 AI 관련 교육이 있어서 내용을 정리 해 두려고 합니다.서울대학교 AI 교수님께서 Multi Modal과 관련된 내용을 하면서 나온 내용의 일부입니다.가장 처음으로 학습한 내용이 바로 Few-Shot Lea
ray5273.tistory.com
Few-Shot Learning에 이어서 포스트를 진행합니다.
이번에는 Zero-shot learning입니다.
Zero-Shot Learning
Few-Shot Learning은 데이터를 많이 주지 않고 몇 개만 주고 데이터를 학습시키겠다는 방법이었습니다.
그런 이름에서 유추할 수 있듯, Zero-Shot Learning은 데이터를 하나도 주지 않고 이게 뭔지를 맞추게 하겠다는 것입니다.
(zero-shot == K-way 0-shot classification)
그러면 하나도 모르는데 어떻게 알지?? 이런 생각이 당연히 듭니다.
Zero-Shot Learning의 의미는 기존과 같이 사진을 통해서 학습이후 학습을 위해 (사진 + Label)의 형태로 추가 학습을 진행을 하는게 아니라, 사진 대신에 다른 문맥적 의미(혹은 메타데이터)를 알려줘서 맞출 수 있게 하겠다는 것입니다.
사람의 경우도 똑같을 수 있는데 아래 예제를 보면 이해가 가능합니다.

우리도 움피묵이라는 것을 맞춰야하는데 우리는 아는 동물이 아니기에 맞출수가 없죠.
사진과 정답을 알려주는 방법도 있겠지만, 움피묵의 특징을 알려주고 맞출 수 도 있겠죠.
- e.g. Wampimuk := small, horns, furry, cute
이런 식으로 움피묵의 특징을 알려주는거죠. (혹은 위키피디아 텍스트를 주는 경우도 많다고 합니다.)
그러면 사진을 보고 맞출 수 있게 됩니다.
이런 방식을 Sementic Transfer라고 하고, Zero-Shot Learning에서 AI에게 주는 데이터입니다.
Sementic Transfer의 Attribute Vector
데이터를 학습 및 추론할때 아래와 같이 attribute vector를 구성해서 전달을 합니다.

흰색이 해당 특징을 가지고 있다는 의미, 검정색이 해당 특징을 가지고 있지 않다는 의미로 보시면 됩니다.
예를 들면, zebra는 black, white, stripes, furry 등등의 특징을 가지고 있고 이를 가지고 있다고 AI에게 벡터로 알려주는것이죠.
연구나 실험시에 자주 쓰이는 데이터 셋은 CUB 데이터 셋이라고 합니다.
새의 데이터 셋이며, 새 마다 Attribute vector를 가지고 있다고 합니다.
https://www.kaggle.com/datasets/wenewone/cub2002011
Zero-shot learning의 학습 방법
1. Category 벡터를 먼저 얻습니다.
- Attribute description (e.g. Wampimuk := small, cute, furry, horns)
- Word-vector (Digested Wikipedia co-occurrence count)
2. 학습하기
- Training set에 대해서 class별 category vector와 이미지를 가집니다.
- AI 모델(e.g. SVM, OLS, DNN) 을 통해서 image to category vector 함수를 만듭니다.
3. Test
- 테스트 클래스에 대해서 vector 함수를 얻습니다.
- 테스트 input에 대해서 테스트를 진행합니다.
Zero-shot Learning의 활용처
등에서 활용한다고 합니다.
다음은 Metric Learning Approach입니다.
Metric Learning Approach
Metric Learning은 데이터 간의 거리를 학습해서 비슷한 단어는 가까운 거리로, 다른 데이터는 먼 거리로 매핑하는 것이 목표입니다.
주요 알고리즘은 Siamese Network, Triplet Loss, Prototypical Networks 등이 있습니다.
먼저 Siamese Network에 대해서 알아보도록 하겠습니다.
1. Siamese Network
- 두 개의 신경망이 같은 가중치를 공유하며 두 입력 데이터의 임베딩을 생성합니다. (Shared Weight)
- 두 임베딩 간 거리를 계산해서 같은 클래스인지 아닌지를 판단하는 방법입니다.
- e.g. 얼굴 인식에서 두개의 사진이 같은 사람인지 아닌지를 확인하는 것

Shared Weight를 적게쓰고 많이 쓰고는 Trade-off 관계라서 선택의 문제입니다.
Siamese Network의 장점
- 데이터를 뻥튀기 가능하다는 장점이 있음 (n Combination 2개의 데이터를 생성 가능 == nC2 )
- 데이터 페이링을 통해서 학습시키는 방식인데
- 데이터가 200개 있다면 200개중에 2개를 고르는 방식으로 데이터를 고르면 대략 2만개가됨
- 주로 쓰이는 곳
- verification에 많이 쓰인다고 합니다.
그 다음은 Triplet Loss입니다.
2. Triplet Loss
용어 정리
- Anchor
- 기준이 되는 데이터 포인트
- 기준 얼굴 사진, 기준 글씨가 anchor가 됨
- Positive
- 의미적으로 유사한 데이터이거나 같은 클래스에 속하는 데이터
- anchor와 같은 클래스에 속하는 데이터
- e.g. 같은 사람의 다른 얼굴 사진
- Negative
- 의미적으로 다른 데이터 쌍
- anchor와 다른 클래스에 속하는 데이터
- e.g. 다른사람 얼굴 사진
Triplet Loss의 목표
Triplet Loss는 아래의 조건을 만족하도록 학습합니다.
- Anchor와 Positive (같은 클래스)는 가깝게
- Anchor와 Negative (다른 클래스)는 멀게
- margin은 Anchor와 Negative 간 최소 거리를 유지하기 위한 하이퍼 파라미터
그래서 위의 값을 Loss function으로 만들면 아래와 같이 됩니다.

- : Anchor와 Positive 간의 거리.
- D(f(ai),f(ni)): Anchor와 Negative 간의 거리.
- max(0,… ): 거리가 margin 조건을 만족하지 않으면, 페널티를 부여.

3. Prototypical Network
쉬운 방법인데 아주 강력한 방법으로 알려져 있습니다.
요약하자면 각 클래스의 "프로토타입"을 계산하여 새로운 샘플이 어떤 클래스에 속하는지 판단하는 방법이라고 합니다.
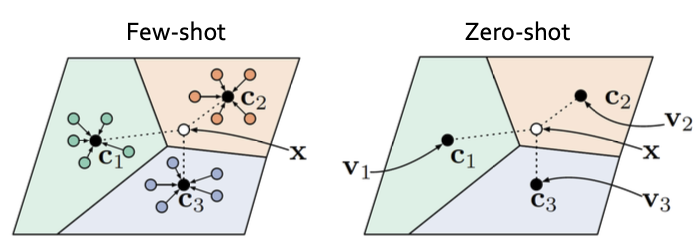
1. Few-shot learning에서는 몇 개의 벡터 샘플을 평균해서 하나의 클래스를 만들고 그것과 input vector와 얼마나 가까운지를 파악하는 방식입니다.
2. Zero-shot에서는 카테고리 vector가 클래스 별로 존재하니까 그 벡터를 새로운 Neural network에 학습하고 그걸 prototype으로 사용합니다.
- query 자체는 이미지라서 학습한 network랑 테스트 데이터랑 다른 input이라고 보면됨.

아주 간단한 방법임에도 불구하고 너무 강력한 성능이라 이를 이기기가 쉽지 않다고 하네요.
따라서, 다른 개선된 논문들에서는 이를 base line 성능으로 두는 경우가 많다고 합니다.
또한, 대부분 이 방법을 통해서 잘 되기 때문에 더 개선 시키려는 의미가 크지 않아 고민이 많다고합니다.
교수님의 AI 최신 트렌드 이야기 2
1. 요즘은 사람들이 만든 데이터가 아닌 생성해낸 합성 (Synthetic) 데이터로 학습을 하고있다.
- NLP는 사람으로 데이터를 모으지 않고 GPT를 활용해서 만든다고합니다.
- 비전쪽도 만들어서 쓰고 있다고 하는데 그 예시 중 하나가 Nvidia의 Omniverse라고 합니다.
- 항상 많이 나오던 주제가 Quality vs Quantity인데 요즘은 실제 데이터 일부 + 많은 합성데이터의 조합을 많이 한다고 하네요
- 예를 들어 대화 데이터를 만드는 경우에 GPT끼리 대화를 시키는 방식으로 대화 데이터를 쌓습니다.
- 사람의 경우 시간당 20달러를 주고 서로 대화를 시키는데, 이 경우에는 서로 친한 사람끼리 대화시키지 않으면 좋은 대화가 나오기가 힘들죠
- 또한, 20달러를 통해서 시켜서 하는일이기에 대화의 성의에 대한 부분도 부족할 수 있습니다.
- 그래서 GPT끼리 대화를 시키는게 더 자연스러워 보이는경우가 많습니다.
- 실제로 설문조사로 사람끼리의 대화 vs GPT 끼리의 대화 중 더 자연스러운 대화가 뭔가 물어보면 GPT끼리의 대화가 더 좋다고 하는 설문조사의 결과가 있다고 하네요
참조
https://en.wikipedia.org/wiki/Zero-shot_learning
Zero-shot learning - Wikipedia
From Wikipedia, the free encyclopedia Problem setup in machine learning Zero-shot learning (ZSL) is a problem setup in deep learning where, at test time, a learner observes samples from classes which were not observed during training, and needs to predict
en.wikipedia.org
'CS 지식 > AI 관련' 카테고리의 다른 글
| Continual Learning, Knowledge Distilation 이해하기 (0) | 2025.02.02 |
|---|---|
| Meta Learning - MAML, Reptile 이해하기 (0) | 2025.01.30 |
| Few-Shot Learning 이해하기 (0) | 2025.01.28 |
| Advanced RAG Techniques - Query expansion, Cross-encoder and Dense Passage Retrieval(DPR) (2) | 2024.12.29 |
| Vector DB란 무엇인가? (3) | 2024.12.26 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



