

Vector DB란?
핵심 요소는 3가지입니다.
1. Vector
2. Dimensionality
3. Similarity Search
Vector란?
수학적으로 방향 (direction)과 크기 (magnitude)가 존재하는 값입니다.
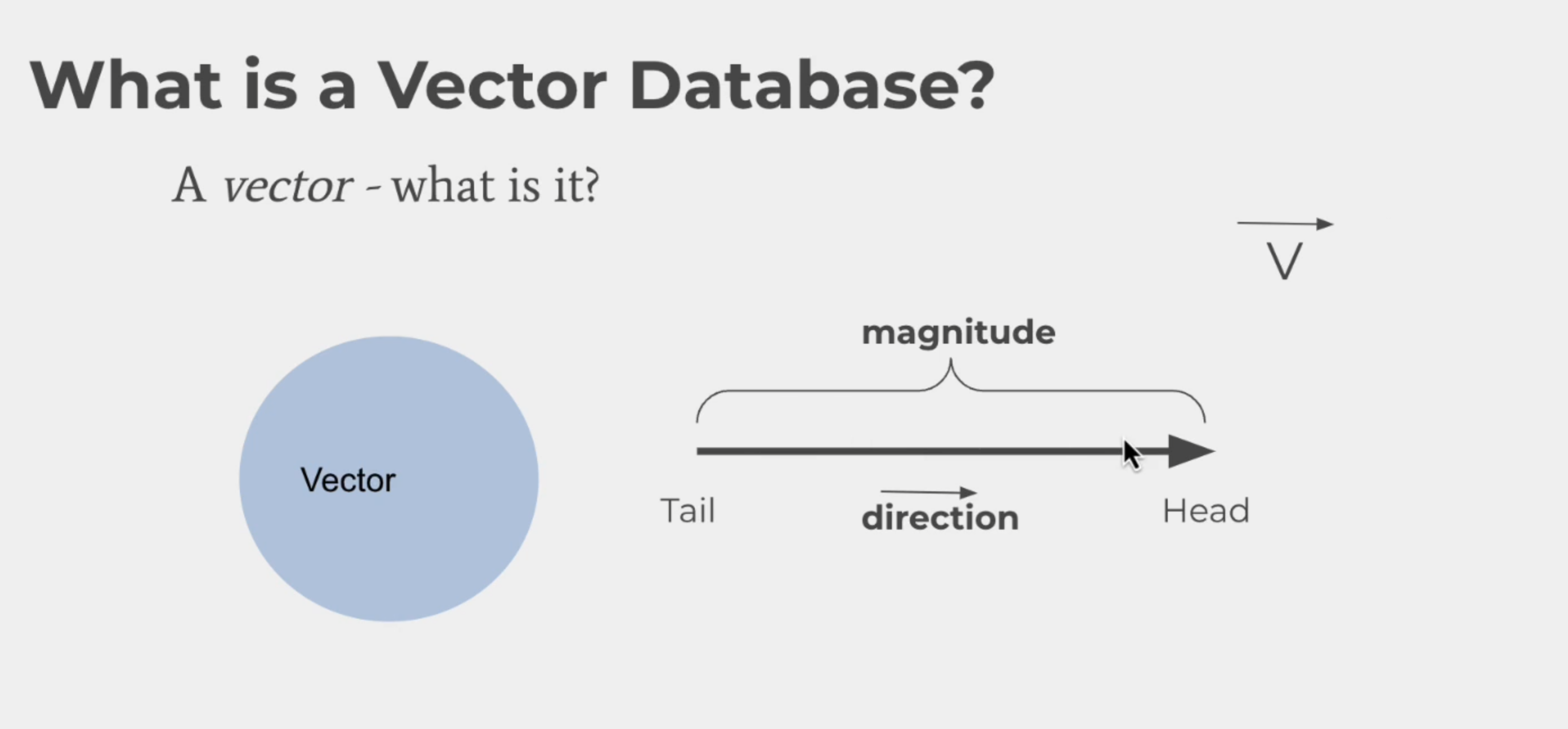

왜 Vector DB를 써야 하는가?
80%의 데이터는 unstructured data입니다.
예를 들면 사진, 음악, PDF, 영상 등이 있죠.
그래서 기존의 Relational DB에 위와 같은 데이터들을 저장하기 위해서는 별도의 메타데이터를 추가하는 등의 작업이 필요합니다.
잘 어울리지는 않는 use case에 가깝죠.
반면 vector DB는 이러한 unstructured data의 저장에 특화되어 있습니다.
왜일까요?
1. 비정형 데이터를 의미 벡터로 변환해 저장
- 임베딩 : 비정형 데이터를 고차원 벡터로 변환해 저장합니다.
- 의미 기반 검색 (Semantic Search) : 같은 문장 또는 유사한 문장을 가진 문장끼리는 유사한 벡터로 매핑됩니다. 이를 통해 키워드가 정확히 일치하지 않아도 의미가 비슷한 데이터들을 빠르게 찾을 수 있습니다.
2. 스키마 설계가 불필요합니다.
- RDB 처럼 테이블 설계가 필요한게 아니라, 데이터마다 임베딩 벡터만 일관성 있게 관리하면 됩니다.
- 텍스트,이미지, 오디오 등 어떤 형태의 비정형 데이터든 임베딩만 되면 바로 저장하고 검색할 수 있습니다.
3. 벡터 인덱스(ANN) 구조 최적화
- ANN 검색 : 벡터 DB는 유사도가 높은 벡터를 빨리 찾을 수 있는 ANN(Approximate Nearest Neighbor) 알고리즘을 활용합니다. HNSW, IVF, Product Quantization 등 다양한 인덱싱 기법 덕분에 수백~수억개의 벡터 데이터도 빠르게 탐색 가능합니다.
왜 vector가 vector DB에서 쓰이는 걸까요?
예시를 통해서 이해해보겠습니다.
campsite를 vector로 표현하자면 아래와 같습니다.
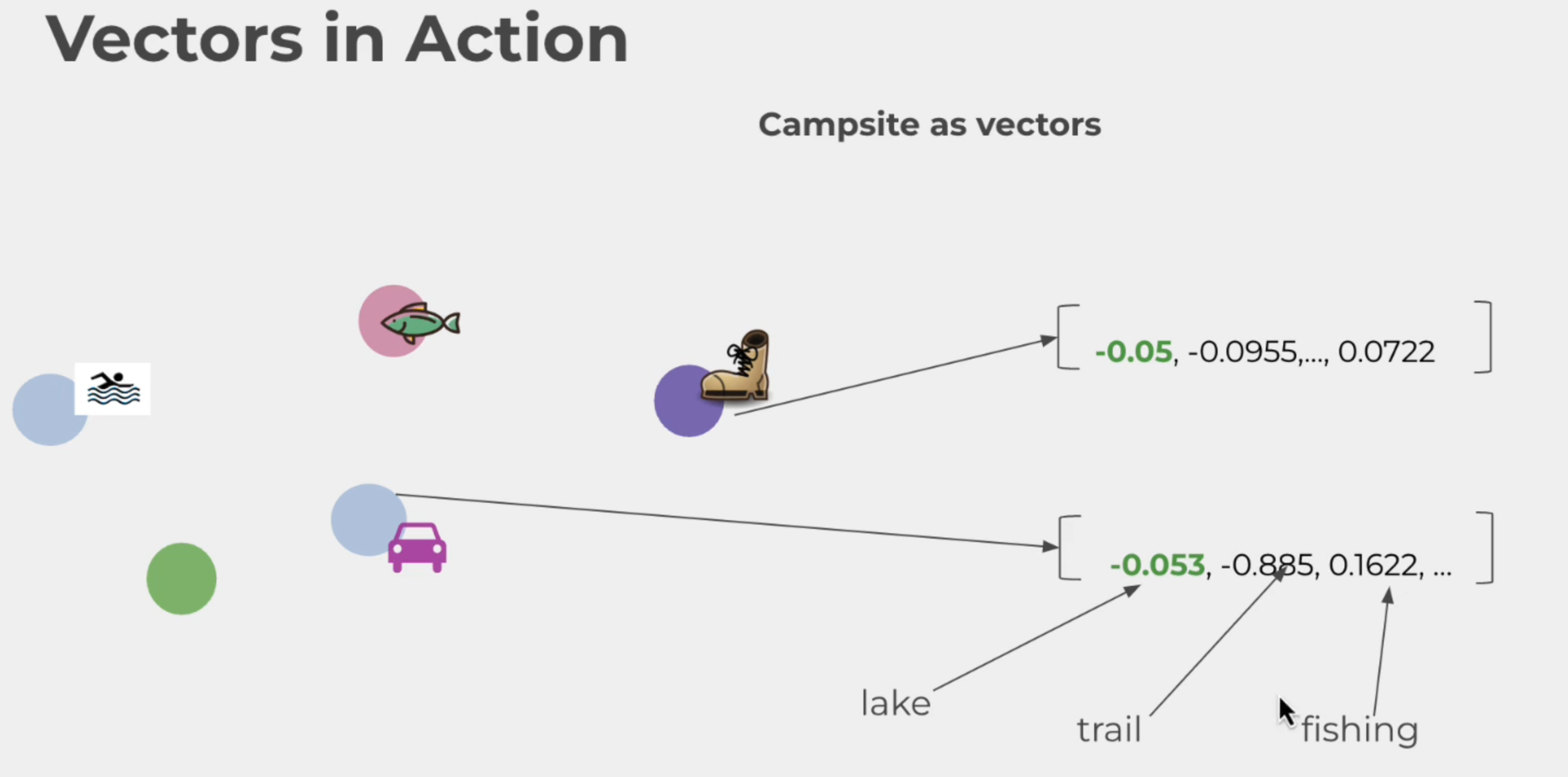
저렇게 숫자로 표현할 수 있게되면 다음에 비슷한 지역/위치를 찾을때 해당 숫자와 비슷한 값을 찾아 검색할 수 있는 것이죠
1. 복잡한 데이터의 효율적인 표현 가능
- Dimensionality - 데이터를 여러 차원의 공간에 표현이 가능함.
- Uniformity - 데이터가 일정한 포맷으로 변환 가능함 (주로, 숫자)
2. Enable Similarity Search
3. 머신러닝 모델을 활용할 수 있음
4. Performance와 Scalability를 Optimize 가능함.
5. User Experience를 향상 가능함
- 실시간 상호작용 (추천, 결과 검색 혹은 데이터 분석 결과)
'CS 지식 > AI 관련' 카테고리의 다른 글
| Zero-shot learning, Metric Learning Approach 이해하기 (0) | 2025.01.28 |
|---|---|
| Few-Shot Learning 이해하기 (0) | 2025.01.28 |
| Advanced RAG Techniques - Query expansion, Cross-encoder and Dense Passage Retrieval(DPR) (2) | 2024.12.29 |
| Vector DB : 전통적인 DB와 비교한 Vector DB의 특징들 (1) | 2024.12.25 |
| Vector DB - Vector Similarity 측정 방법 3가지 (0) | 2024.12.22 |
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



