

Vector DB : 전통적인 DB와 비교한 Vector DB의 특징들CS 지식/AI 관련2024. 12. 25. 11:19
Table of Contents
반응형
Vector DB에 대해서 정리 하면서 궁금한점을 중간 중간에 추가해 두었고 그에 대한 답도 추가해 두었습니다.
전통 DB의 특징
- RDBMS 기반입니다.
- Structured data 입니다 - predefined column과 row가 있습니다.
- Schema-based - database structure는 사용전에 미리 정의되어야 합니다.
- Data manipulation and querying - SQL로 데이터를 조작해야함.
- ACID Compliant - Atomicity, Consistency, Isolation, Durability를 보장해야함.
- Indexing - 데이터 검색 및 가져오기를 빠르게 하기 위함.

전통 DB의 한계
- Scalability - 큰 테이블에 대해서 복잡한 쿼리를 처리하는데 어렵다.
- Flexibility - DB 스키마 변경이 쉽지 않다.
- Unstructured Data 처리가 힘들다 - 이미지, 텍스트, 음악, 비디오 등의 처리가 힘들다.
Unstructured data를 Vector로 변경의 Deep Dive
아이디어는 데이터를 쪼개서 Embedding하여 Embedding vector를 만들어서 vector DB에 저장 하는 것입니다.
아래와 같이요

Embedding vector는 텍스트의 의미와 정보를 포함하고 있습니다.
그러니 비슷한 컨텐츠와 의미는 비슷한 vector를 가지게 됩니다.

Vector DB에 데이터를 저장하는 전체 Overview

Vector DB에 데이터를 Query 하는 과정

의문
1. 질문과 실제 답은 다른 방식으로 embedding 되고 저장될텐데 그 두개를 서로 연관을 어떻게 짓는건지 궁금하다.
=> 같은 Embedding model을 통해서 저장 되는 것으로 보인다. (텍스트는 텍스트 embedding 모델사용, 각 목적에 맞는 embedding model 사용
=> LLM 모델이 이를 감싸서 query에 대한 response를 처리해주는듯.
2. vector db의 index가 뭐지?
=> vector 값을 자체를 의미하는것은 아님
=> vector를 쉽게 검색 하기 위한 추가적인 자료구조라고 함.
예: HNSW(그래프 기반), IVF-PQ, Annoy, Faiss 등
빠른 최근접 이웃(Nearest Neighbor) 검색을 위해 벡터들을 특정 방식으로 조직화
벡터만 단순 보관할 때보다 훨씬 빠르게 유사 벡터를 찾을 수 있음
Vector DB가 LLM에서 작동하는 방식

Embedding 과 vector의 차이
- Vectors - generic하고 넓은 범위의 어플리케이션에서 쓸 수 있습니다.
- Embedding - raw data를 vector space로 mapping 해줍니다.
(의미 관계를 유지하는 역할을 합니다. - 이는 AI에서 중요한 역할을 합니다.)
결론은 Embedding은 vector이지만, 모든 벡터는 embedding이 아닙니다.
Vector DB가 동작하는 방식

위와 같은 그림으로 동작합니다.
1. Vector DB에 저장 하고 싶은 데이터를 Embedding model에 넣어서 vector화 시킵니다.
2. Vector DB에 해당 vector를 저장합니다.
3. Vector DB에 Query를 던지기 위해서 Query 또한 Embedding model에 넣어서 vector화 시킵니다.
4. Similarity 알고리즘을 통해서 (e.g. Cosine, Euclidean) Vector DB에 저장된 vector들과 3에서 계산한 vector를 비교합니다.
5. 가장 비슷한 결과를 출력 받습니다.
장점
- Vector로 데이터 표현이 가능합니다 - vector로 저장하면 검색에 많은 이점을 줍니다.
- Similarity Search - 비슷한 데이터를 찾을 수 있습니다.
- 고차원 검색의 효율이 좋습니다 - 특별한 indexing 구조를 통해서 최적화 했습니다.
- Unstructured Data
- Schema-less Design - 스키마가 필요없습니다. 다양한 데이터타입과 structure를 이용할 수 있습니다.
Vector DB의 Use case
복잡한 query에 좋습니다.
1. 이미지 검색과 유사성 검사

2. 추천 시스템

3. 자연어 처리 (Natural Language Processing)
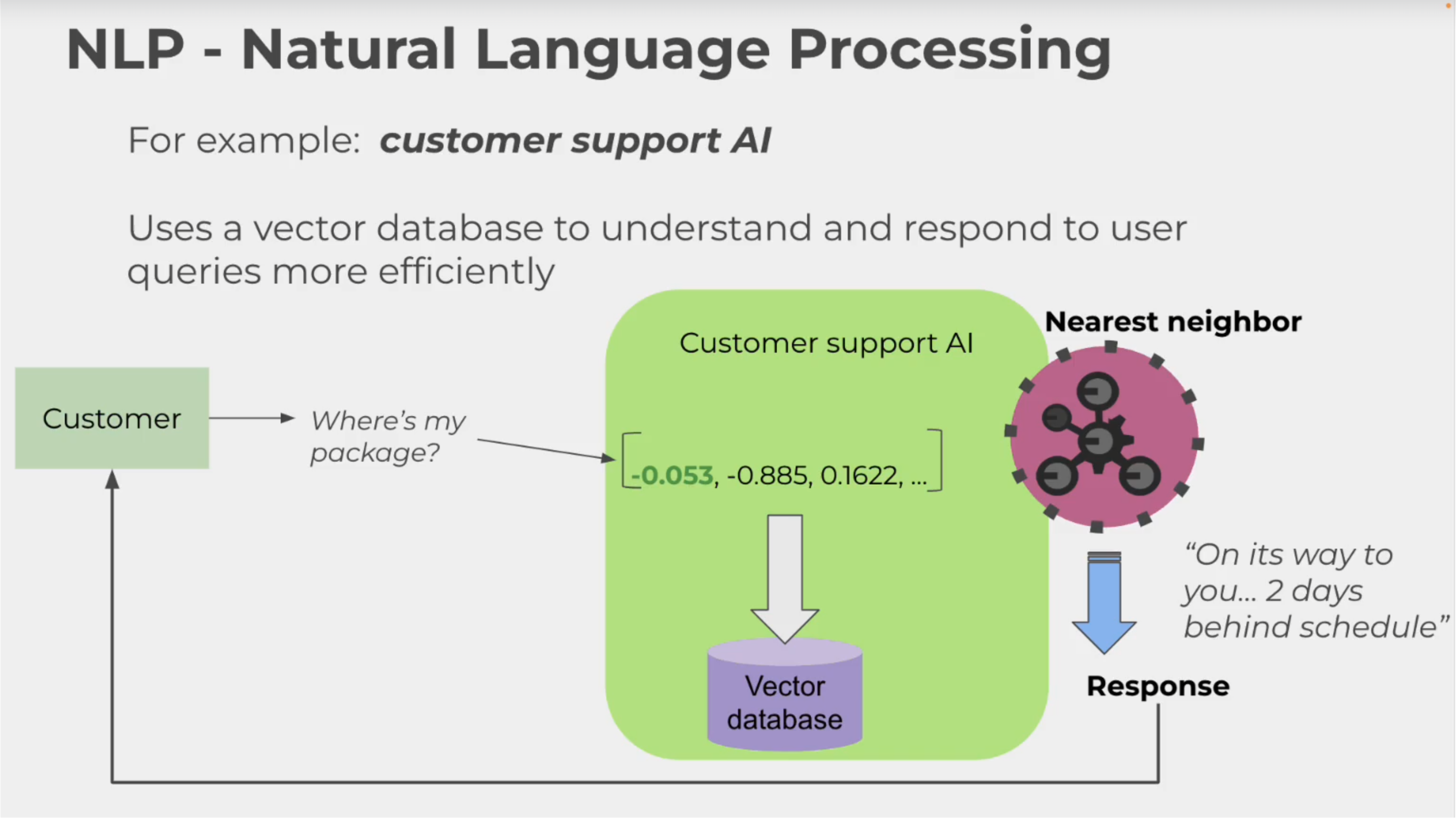
4. 사기 탐지 (Fraud Detection) & Bioinformatics

Vector DB의 종류 및 비교




적절한 Vector DB 선택의 기준

반응형
'CS 지식 > AI 관련' 카테고리의 다른 글
| Zero-shot learning, Metric Learning Approach 이해하기 (0) | 2025.01.28 |
|---|---|
| Few-Shot Learning 이해하기 (0) | 2025.01.28 |
| Advanced RAG Techniques - Query expansion, Cross-encoder and Dense Passage Retrieval(DPR) (2) | 2024.12.29 |
| Vector DB란 무엇인가? (3) | 2024.12.26 |
| Vector DB - Vector Similarity 측정 방법 3가지 (0) | 2024.12.22 |
@ray5273 :: Micro Changes, Macro Impact
개발 및 IT 관련 포스팅을 작성 하는 블로그입니다.
IT 기술 및 개인 개발에 대한 내용을 작성하는 블로그입니다. 많은 분들과 소통하며 의견을 나누고 싶습니다.



